1. Basic Components of the File System#
The Linux file system allocates two data structures for each file: inode and directory entry, which are mainly used to record the file's metadata and directory hierarchy.
- The inode is used to record the file's metadata, such as inode number, file size, access permissions, creation time, modification time, data location on disk, etc. The inode is the unique identifier for a file, and they correspond one-to-one, and they are also stored on the hard disk, so inodes also occupy disk space.
- The directory entry is used to record the file name, inode pointer, and hierarchical relationships with other directory entries. When multiple directory entries are linked together, they form a directory structure. However, unlike inodes, directory entries are a data structure maintained by the kernel, not stored on disk, but cached in memory.
Since inodes uniquely identify a file and directory entries record the file name, the relationship between directory entries and inodes is many-to-one, meaning a file can have multiple aliases. For example, the implementation of hard links is that multiple directory entries' inodes point to the same file.
Note that a directory is also a file, uniquely identified by an inode. Unlike regular files, which store file data on disk, directory files store subdirectories or files on disk.
Are directory entries and directories the same thing?
Although the names are similar, they are not the same. A directory is a file, persistently stored on disk, while a directory entry is a data structure in the kernel, cached in memory.
If directory queries frequently read from disk, efficiency will be very low, so the kernel caches directories that have been read using the directory entry data structure. The next time the same directory is read, it can be read from memory, greatly improving the efficiency of the file system.
Note that the directory entry data structure not only represents directories but can also represent files.
How is file data stored on disk?
The smallest unit of disk read/write is sector, which is only 512B in size. Clearly, if every read/write operation is done at such a small unit, the efficiency would be very low.
Therefore, the file system groups multiple sectors into a logical block, and the smallest unit for read/write operations is the logical block (data block). The logical block size in Linux is 4KB, which means reading and writing 8 sectors at a time, significantly improving the efficiency of disk read/write operations.
This explains the relationship between inodes, directory entries, and file data. The following diagram illustrates their relationships well:

Inodes are stored on the hard disk, so to speed up file access, they are usually loaded into memory.
Additionally, when a disk is formatted, it is divided into three storage areas: the superblock, the inode area, and the data block area.
- The superblock stores detailed information about the file system, such as the number of blocks, block size, free blocks, etc.
- The inode area is used to store inodes;
- The data block area is used to store file or directory data;
We cannot load the entire superblock and inode area into memory, as that would overwhelm the memory. Therefore, they are only loaded into memory when needed, and the timing for loading them into memory is different:
- Superblock: Loaded into memory when the file system is mounted;
- Inode area: Loaded into memory when a file is accessed;
2. Virtual File System#
There are many types of file systems, and the operating system wants to provide a unified interface to users, so an intermediate layer is introduced between the user layer and the file system layer, called the Virtual File System (VFS).
VFS defines a set of data structures and standard interfaces supported by all file systems, so programmers do not need to understand how file systems work; they only need to understand the unified interface provided by VFS.
In the Linux file system, the relationships between user space, system calls, virtual file systems, caches, file systems, and storage are shown in the following diagram:
Linux supports a variety of file systems, which can be divided into three categories based on storage location:
- Disk file systems, which store data directly on the disk, such as Ext 2/3/4, XFS, etc.
- Memory file systems, which do not store data on the hard disk but occupy memory space. The
/procand/sysfile systems we often use belong to this category. Reading and writing these files actually reads and writes related data in the kernel. - Network file systems, which are used to access data from other computer hosts, such as NFS, SMB, etc.
File systems must first be mounted to a directory to be used normally. For example, during the startup of a Linux system, the file system is mounted to the root directory.
3. File Usage#
From the user's perspective, how do we use files? First, we need to open a file through a system call.

The process of reading a file:
- First, use the
opensystem call to open the file, withopen's parameters including the file path and file name. - Use
writeto write data, wherewriteuses the file descriptor returned byopen, not the file name as a parameter. - After using the file, the
closesystem call must be used to close the file to avoid resource leakage.
Once we open a file, the operating system tracks all files opened by the process. Tracking means the operating system maintains an open file table for each process, where each entry represents a file descriptor, so the file descriptor is the identifier for the opened file.
The operating system maintains the status and information of opened files in the open file table:
- File pointer: The system tracks the last read/write position as the current file position pointer, which is unique to a certain process for the opened file;
- File open counter: When a file is closed, the operating system must reuse its open file table entry; otherwise, there won't be enough space in the table. Since multiple processes may open the same file, the system must wait for the last process to close the file before deleting the opened file entry. This counter tracks the number of opens and closes, and when the count reaches 0, the system closes the file and deletes the entry;
- File disk location: Most file operations require the system to modify file data, and this information is stored in memory to avoid reading from the disk for every operation;
- Access permissions: Each process opening a file needs an access mode (create, read-only, read-write, append, etc.), and this information is stored in the process's open file table so that the operating system can allow or deny subsequent I/O requests;
From the user's perspective, a file is a persistent data structure, but the operating system does not care about any data structure you want to exist on the disk. The operating system's perspective is how to map file data to disk blocks.
Thus, the read and write operations of files differ between users and the operating system. Users are accustomed to reading and writing files in bytes, while the operating system reads and writes files in data blocks. The file system is responsible for masking this difference.
Let's look at the processes of reading and writing files:
- When a user process reads 1 byte of data from a file, the file system needs to obtain the data block where the byte is located and then return the corresponding part of the data block to the user process.
- When a user process writes 1 byte of data to a file, the file system finds the location of the data block where the data needs to be written, modifies the corresponding part of the data block, and then writes the data block back to the disk.
Thus, the basic operational unit of the file system is the data block.
4. File Storage#
1. Contiguous Space Storage Method#
The contiguous space storage method, as the name implies, stores files in "contiguous" physical space on the disk. In this mode, the file data is tightly connected, and the read/write efficiency is very high because an entire file can be read out with a single disk seek.
Using the contiguous storage method has a prerequisite: the size of a file must be known in advance so that the file system can find a contiguous space on the disk based on the file size to allocate for the file.
Therefore, the file header needs to specify the "starting block position" and "length". With this information, it can represent that the file storage method is a contiguous disk space.
Note that the file header mentioned here is similar to the inode in Linux.

Although the contiguous storage method has high read/write efficiency, it has the drawbacks of "disk space fragmentation" and "difficulty in expanding file length."
2. Non-contiguous Space Storage Method#
Linked List Method#
The linked list storage method is discrete, not continuous, which can eliminate disk fragmentation, greatly improving the utilization of disk space, and the length of the file can be dynamically expanded.
Implicit Linked List
The implementation requires the file header to include the positions of the "first block" and "last block," and each data block leaves space for a pointer to store the position of the next data block. This way, one data block is linked to another, and starting from the head of the chain, all data blocks can be found by following the pointers, so the storage method can be non-contiguous.

The disadvantage of the implicit linked list storage method is that it cannot directly access data blocks; it can only access the file sequentially through pointers, and the data block pointers consume some storage space. The stability of implicit linked allocation is relatively poor; if software or hardware errors occur during system operation, the loss or damage of pointers in the linked list can lead to data loss.
Explicit Linking
This means the pointers used to link the data blocks of the file are explicitly stored in a link table in memory, with only one such table set up for the entire disk, each table entry stores a link pointer pointing to the next data block number.
For the working method of explicit linking, let's take an example: File A uses disk blocks 4, 7, 2, 10, and 12 in sequence, while File B uses disk blocks 6, 3, 11, and 14 in sequence. Using the table in the diagram below, we can start from block 4 and follow the chain to find all the disk blocks of File A. Similarly, starting from block 6 and following the chain to the end can also find all the disk blocks of File B. Finally, both chains end with a special marker (like -1) that does not belong to a valid disk number. This table in memory is called the File Allocation Table (FAT).

Since the lookup process is done in memory, it not only significantly improves retrieval speed but also greatly reduces the number of disk accesses. However, because the entire table is stored in memory, its main disadvantage is that it is not suitable for large disks.
For example, for a 200GB disk with a block size of 1KB, this table would need 200 million entries, each corresponding to one of the 200 million disk blocks. If each entry requires 4 bytes, this table would occupy 800MB of memory, which is clearly not suitable for large disks.
Indexing Method#
The indexing method creates an index data block for each file, which contains a list of pointers pointing to the file's data blocks, similar to a table of contents in a book; to find the content of a chapter, you can check the table.
Additionally, the file header needs to include a pointer to the "index data block," so that the position of the index data block can be known through the file header, and then the corresponding data block can be found through the index information in the index data block.
When a file is created, all pointers in the index block are set to null. When the first write occurs to the i-th block, a block is obtained from free space, and its address is written to the i-th entry of the index block.

The advantages of the indexing method are:
- Creating, enlarging, and shrinking files is very convenient;
- There will be no fragmentation issues;
- Supports both sequential and random read/write;
Since index data is also stored in disk blocks, if a file is very small and can fit in just one block, an extra block is still needed to store index data, so one of the drawbacks is the overhead of storing the index.
Chained Index Blocks
If a file is very large, to the extent that one index data block cannot hold all the index information, how can we handle the storage of large files? We can use a combination method to handle large file storage.
First, let's look at the combination of linked list + index, which is called chained index blocks. Its implementation method is to leave a pointer in the index data block to store the next index data block, so when the index data block's index information is exhausted, it can find the next index data block's information through the pointer. However, this method also has the problems mentioned earlier with linked lists; if a pointer is damaged, subsequent data will be unreadable.

Another combination method is the index + index method, which is called multi-level index blocks. Its implementation method is to use one index block to store multiple index data blocks, creating layers of indexes, much like Russian nesting dolls.

3. Implementation of Unix Files#
The storage method varies based on the file size:
- If the number of data blocks required to store the file is less than 10 blocks, direct lookup is used;
- If the number of data blocks required to store the file exceeds 10 blocks, a single indirect indexing method is used;
- If the first two methods are insufficient to store large files, a double indirect indexing method is used;
- If the double indirect indexing is also insufficient to store large files, a triple indirect indexing method is used;
Thus, the file header (inode) needs to contain 13 pointers:
- 10 pointers to data blocks;
- The 11th pointer to the index block;
- The 12th pointer to the secondary index block;
- The 13th pointer to the tertiary index block;
This method can flexibly support the storage of both small and large files:
- For small files, using direct lookup can reduce the overhead of index data blocks;
- For large files, multi-level indexing is used to support them, so accessing data blocks for large files requires many queries.
4. Free Space Management#
If I want to save a data block, where should I place it on the hard disk? Do I need to scan all the blocks to find an empty place to put it?
That method would be too inefficient, so a management mechanism must be introduced for the free space on the disk. Here are a few common methods:
- Free table method
- Free linked list method
- Bitmap method
Free Table Method#
The free table method establishes a table for all free spaces, with the table contents including the first block number of the free area and the number of blocks in that free area. Note that this method is for contiguous allocation. As shown in the diagram:

When a request for disk space allocation is made, the system scans the contents of the free table in order until it finds a suitable free area. When a user cancels a file, the system reclaims the file space. At this time, it also needs to sequentially scan the free table to find a free table entry and fill in the first physical block number of the released space and the number of blocks it occupies into that entry.
This method works well only when there are a small number of free areas. If there are many small free areas in the storage space, the free table becomes very large, making query efficiency very low. Additionally, this allocation technique is suitable for establishing contiguous files.
Free Linked List Method#
We can also use a "linked list" method to manage free space, where each free block has a pointer pointing to the next free block, making it easy to find and manage free blocks. As shown in the diagram:

When creating a file that requires one or more blocks, it takes the next block or blocks from the head of the chain. Conversely, when reclaiming space, these free blocks are sequentially attached to the head of the chain.
This technique only requires a pointer to be saved in main memory, pointing to the first free block. Its characteristics are simplicity, but it cannot be accessed randomly, and its work efficiency is low because many I/O operations are needed whenever free blocks are added or moved on the chain, and the data block pointers consume some storage space.
Both the free table method and the free linked list method are not suitable for large file systems, as they would make the free table or free linked list too large.
Bitmap Method#
A bitmap uses a single binary bit to represent the usage status of a disk block, with each disk block corresponding to a binary bit.
When the value is 0, it indicates that the corresponding disk block is free; when the value is 1, it indicates that the corresponding disk block is allocated. It takes the following form:
1111110011111110001110110111111100111 ...
The Linux file system uses the bitmap method to manage free space, not only for managing free data blocks but also for managing free inodes, as inodes are also stored on disk and naturally need management.
5. Structure of the File System#
When a user creates a new file, the Linux kernel finds an available inode through the inode bitmap and allocates it. To store data, it finds free blocks through the block bitmap and allocates them, but careful calculations reveal that there are still issues.
The data block bitmap is stored in disk blocks, assuming it is stored in one block, one block is 4K, and each bit represents a data block, which can represent a total of 4 * 1024 * 8 = 2^15 free blocks. Since one data block is 4K in size, the maximum representable space is 2^15 * 4 * 1024 = 2^27 bytes, which is 128M.
This means that according to the structure above, if a "bitmap of one block + a series of blocks" is used, along with "a block of inode bitmap + a series of inode structures," the maximum space that can be represented is only 128M, which is too small, as many files are larger than this.
In the Linux file system, this structure is called a block group. With N block groups, it can represent N large files.
The diagram below shows the structure of the entire Linux Ext2 file system and the contents of the block groups, which consist of many block groups arranged sequentially on the hard disk:

The first block at the front is the boot block, used to enable booting when the system starts, followed by a series of contiguous block groups. The contents of a block group are as follows:
- The superblock contains important information about the file system, such as the total number of inodes, total number of blocks, number of inodes per block group, number of blocks per block group, etc.
- The block group descriptor contains the status of each block group in the file system, such as the number of free blocks and inodes in the block group. Each block group contains "descriptor information for all block groups" in the file system.
- The data bitmap and inode bitmap are used to indicate whether the corresponding data block or inode is free or in use.
- The inode list contains all the inodes in the block group, which are used to store all metadata related to files and directories in the file system.
- The data blocks contain useful data for files.
You may notice that there is a lot of redundant information in each block group, such as the superblock and block group descriptor table, both of which are global information and very important. This is done for two reasons: - If the system crashes and damages the superblock or block group descriptor, all information related to the file system structure and content will be lost. If there are redundant copies, that information may be recoverable.
- By keeping files and management data as close as possible, the seek and rotation of the disk head are reduced, which can improve the performance of the file system.
However, subsequent versions of Ext2 adopted sparse technology. This approach means that the superblock and block group descriptor table are no longer stored in every block group of the file system but are only written to block group 0, block group 1, and other block groups whose IDs can be expressed as powers of 3, 5, and 7.
6. Directory Storage#
The blocks of ordinary files store file data, while the blocks of directory files store information about the files in the directory.
In the blocks of directory files, the simplest storage format is a list, where the file information (such as file name, file inode, file type, etc.) under the directory is listed one by one.
Each item in the list represents the file name and corresponding inode of the file under that directory, and through this inode, the actual file can be found.

Typically, the first item is ".", representing the current directory, and the second item is "..", representing the parent directory, followed by the file names and inodes one by one.
If a directory has a large number of files, searching for a file in that directory by going through the list one by one would be inefficient.
Thus, the storage format of directories is changed to a hash table, where file names are hashed, and the hash values are stored. If we want to find a file name under a directory, we can hash the name. If the hash matches, it indicates that the file information is in the corresponding block.
The ext file system in the Linux system uses a hash table to store directory contents. The advantage of this method is that searching is very fast, and insertion and deletion are also relatively simple, but some preparatory measures are needed to avoid hash collisions.
Directory queries are completed by repeatedly searching on the disk, requiring constant I/O operations, which incurs significant overhead. Therefore, to reduce I/O operations, the currently used file directory is cached in memory. When the file is needed again, it can be operated in memory, thus reducing the number of disk operations and improving the speed of file system access.
7. Soft Links and Hard Links#
Sometimes we want to give a file an alias, which can be achieved in Linux through hard links and soft links. They are both special types of files, but their implementation methods are different.
Hard Links#
Hard links are multiple directory entries' "inodes" pointing to one file, meaning they point to the same inode. However, inodes cannot cross file systems, as each file system has its own inode data structure and list, so hard links cannot be used across file systems. Since multiple directory entries point to one inode, the system will only completely delete the file when all hard links and the source file are deleted.

Soft Links#
Soft links are equivalent to creating a new file, which has an independent inode, but the content of this file is the path of another file, so accessing the soft link actually accesses another file. Thus, soft links can cross file systems, and even if the target file is deleted, the link file still exists, but it just points to a file that cannot be found.

8. File I/O#
File read and write methods have their own merits, and there are many classifications for file I/O, commonly including:
- Buffered and unbuffered I/O
- Direct and non-direct I/O
- Blocking and non-blocking I/O vs. synchronous and asynchronous I/O
Buffered and Unbuffered I/O#
The standard library for file operations can implement data caching, so based on "whether to use standard library buffering," file I/O can be divided into buffered I/O and unbuffered I/O:
- Buffered I/O uses the standard library's cache to speed up file access, while the standard library accesses files through system calls.
- Unbuffered I/O accesses files directly through system calls without going through the standard library cache.
Here, "buffered" specifically refers to the buffering implemented internally by the standard library.
For example, many programs only actually output when encountering a newline, while the content before the newline is temporarily cached by the standard library. The purpose of this is to reduce the number of system calls, as system calls incur the overhead of CPU context switching.
Direct and Non-direct I/O#
We know that disk I/O is very slow, so the Linux kernel reduces the number of disk I/O operations by copying user data into kernel cache after system calls. This kernel cache space is called "page cache," and disk I/O requests are only initiated when the cache meets certain conditions.
Thus, based on "whether to use the operating system's cache," file I/O can be divided into direct I/O and non-direct I/O:
- Direct I/O does not involve data copying between the kernel cache and user programs but accesses the disk directly through the file system.
- Non-direct I/O, during read operations, copies data from the kernel cache to the user program, and during write operations, copies data from the user program to the kernel cache, with the kernel deciding when to write data to the disk.
If you specify the O_DIRECT flag when using file operation system call functions, it indicates the use of direct I/O. If not set, the default is non-direct I/O.
When using non-direct I/O for write operations, under what circumstances will the kernel write cached data to the disk?
The following scenarios will trigger the kernel to write cached data to the disk:
- At the end of the
writecall, when the kernel finds that there is too much cached data, it will write the data to the disk; - The user actively calls
sync, causing the kernel cache to flush to the disk; - When memory is very tight and cannot allocate more pages, it will also flush the kernel cache data to the disk;
- When the cached data has exceeded a certain time limit, it will also flush the data to the disk;
Blocking and Non-blocking I/O vs. Synchronous and Asynchronous I/O#
Why are blocking/non-blocking and synchronous/asynchronous discussed together? Because they are indeed very similar and easily confused, but their relationships are somewhat subtle.
First, let's look at blocking I/O. When a user program executes read, the thread will be blocked, waiting until the kernel data is ready and the data is copied from the kernel buffer to the application program's buffer. Only after the copy process is complete will read return.
Note that blocking waits for both "kernel data to be ready" and "data to be copied from kernel mode to user mode." The process is illustrated in the diagram below:

Now that we understand blocking I/O, let's look at non-blocking I/O. A non-blocking read request immediately returns when the data is not ready, allowing the application program to continue executing. At this point, the application program continuously polls the kernel until the data is ready, and only then can the read call obtain the result. The process is illustrated in the diagram below:
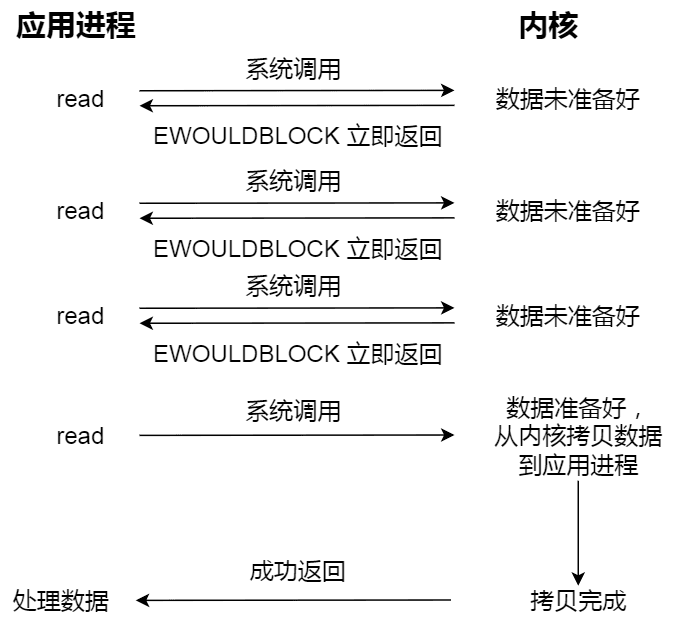
Note that the last read call to obtain data is a synchronous process, which requires waiting. This synchronization refers to the process of copying data from kernel mode to the user program's buffer.
For example, when accessing a pipe or socket, if the O_NONBLOCK flag is set, it indicates that non-blocking I/O is being used. If no settings are made, the default is blocking I/O.
Polling the kernel for I/O readiness each time seems a bit silly, as the application does nothing during the polling process, just loops.
To solve this silly polling method, the I/O multiplexing technology was introduced, such as select and poll, which dispatch I/O events. When kernel data is ready, it notifies the application program to perform operations.
This greatly improves CPU utilization because when an I/O multiplexing interface is called, if no events occur, the current thread will block, allowing the CPU to switch to execute other threads. When the kernel detects an incoming event, it wakes up the thread blocked on the I/O multiplexing interface, allowing the user to perform subsequent event handling.
The entire process is more complex than blocking I/O and seems to waste more performance. However, the biggest advantage of the I/O multiplexing interface is that users can handle multiple socket I/O requests simultaneously within a single thread (see: I/O Multiplexing: select/poll/epoll (opens new window)). Users can register multiple sockets and continuously call the I/O multiplexing interface to read activated sockets, achieving the goal of handling multiple I/O requests in the same thread. In the synchronous blocking model, this can only be achieved through multithreading.
The following diagram illustrates the process of using select I/O multiplexing. Note that the read process of obtaining data (the process of copying data from kernel mode to user mode) is also a synchronous process that requires waiting:
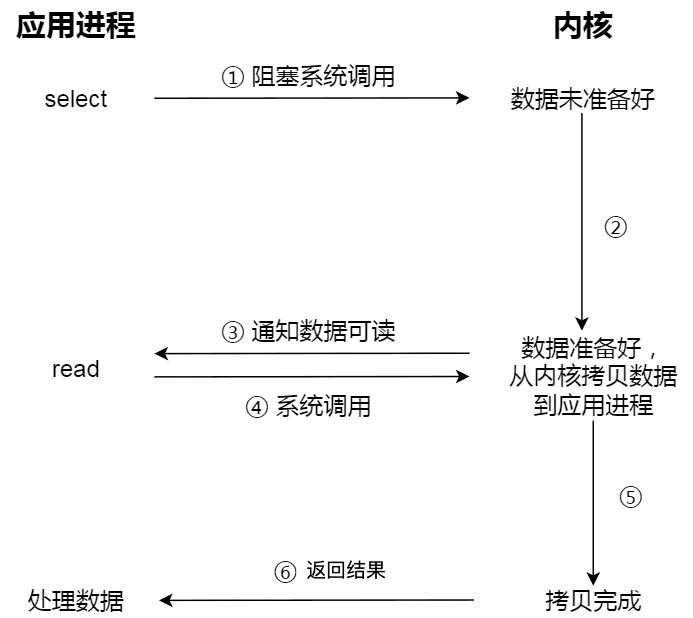
In fact, whether it is blocking I/O, non-blocking I/O, or I/O multiplexing based on non-blocking I/O, they are all synchronous calls. Because during the read call, the kernel copies data from kernel space to application space, and this process requires waiting, meaning this process is synchronous. If the kernel's implementation of the copy is not efficient, the read call may wait a long time during this synchronous process.
True asynchronous I/O means that neither the "kernel data is ready" nor the "data is copied from kernel mode to user mode" processes need to wait.
When we initiate aio_read, it immediately returns, and the kernel automatically copies data from kernel space to application space. This copy process is also asynchronous, automatically completed by the kernel, unlike the previous synchronous operations where the application program needs to actively initiate the copy action. The process is illustrated in the diagram below:

The following diagram summarizes the various I/O models discussed above:
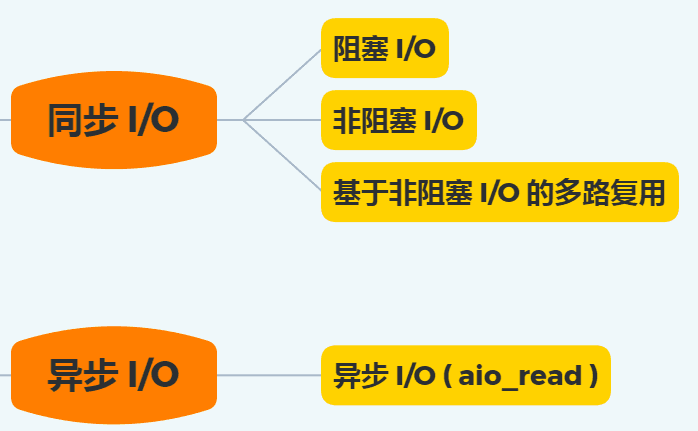
Earlier, we learned that I/O is divided into two processes:
- The process of preparing data
- The process of copying data from kernel space to user process buffer
Blocking I/O will block on "process 1" and "process 2," while non-blocking I/O and I/O multiplexing based on non-blocking I/O will only block on "process 2." Therefore, these three can all be considered synchronous I/O.
Asynchronous I/O, on the other hand, does not block either "process 1" or "process 2."
9. Page Cache#
What is Page Cache?#
To understand Page Cache, let's first look at the Linux file I/O system, as shown in the diagram below:

In the diagram, the red part represents Page Cache. It can be seen that the essence of Page Cache is a memory area managed by the Linux kernel. When we read files into memory using mmap and buffered I/O, we are actually reading into Page Cache.
How to View System Page Cache?#
By reading the /proc/meminfo file, we can obtain real-time information about the system's memory:
$ cat /proc/meminfo
...
Buffers: 1224 kB
Cached: 111472 kB
SwapCached: 36364 kB
Active: 6224232 kB
Inactive: 979432 kB
Active(anon): 6173036 kB
Inactive(anon): 927932 kB
Active(file): 51196 kB
Inactive(file): 51500 kB
...
Shmem: 10000 kB
...
SReclaimable: 43532 kB
...
Based on the above data, you can derive a simple formula (the sum on both sides is 112696 KB):
Buffers + Cached + SwapCached = Active(file) + Inactive(file) + Shmem + SwapCached
Both sides of the equation represent Page Cache, that is:
Page Cache = Buffers + Cached + SwapCached
By reading the following sections, you will understand why SwapCached and Buffers are also part of Page Cache.
Page and Page Cache#
A page is the basic unit of memory management allocation, and Page Cache is composed of multiple pages. The size of a page in operating systems is typically 4KB (32bits/64bits), while the size of Page Cache is an integer multiple of 4KB.
On the other hand, not all pages are organized as Page Cache.
The memory accessible to users in Linux systems is divided into two types:
- File-backed pages: These are the pages in Page Cache that correspond to several data blocks on disk; the main issue with these pages is dirty page flushing.
- Anonymous pages: These do not correspond to any disk data blocks and are the memory space for the process's execution (e.g., method stacks, local variable tables, etc.);
Why doesn't Linux call Page Cache block cache? Wouldn't that be better?
This is because the data loaded from the disk into memory is not only placed in Page Cache but also in buffer cache.
For example, disk files accessed through Direct I/O technology will not enter Page Cache. Of course, this issue also has historical design reasons in Linux; after all, this is just a name, and its meaning has gradually changed with the evolution of the Linux system.
Next, let's compare the performance of File-backed pages and Anonymous pages under the Swap mechanism.
Memory is a precious resource, and when memory is insufficient, the Memory Management Unit (MMU) needs to provide scheduling algorithms to reclaim relevant memory space. The method of reclaiming memory space is usually through swap, that is, swapping to persistent storage devices.
File-backed pages (Page Cache) have a lower cost of memory reclamation. Page Cache typically corresponds to several sequential blocks on a file, so it can be flushed to disk through sequential I/O. On the other hand, if no write operations are performed on Page Cache (meaning there are no dirty pages), Page Cache may not even need to be flushed, as the contents can be obtained by reading the disk file again.
The main difficulty with Page Cache lies in dirty page flushing, which will be explained in detail later.
Anonymous pages have a higher cost of memory reclamation. This is because Anonymous pages are usually written to persistent swap devices randomly. Additionally, regardless of whether there are write operations, to ensure data is not lost, Anonymous pages must be persisted to disk during swap.
Swap and Page Faults#
The Swap mechanism refers to the process where, when physical memory is insufficient, the Memory Management Unit (MMU) needs to provide scheduling algorithms to reclaim relevant memory space and then allocate the reclaimed memory space to the current memory requester.
The essence of the Swap mechanism is that the Linux system provides a virtual memory management mechanism, where each process believes it has exclusive memory space, so the total memory space of all processes far exceeds the physical memory. The portion of the total memory space that exceeds physical memory needs to be swapped to disk.
The operating system manages memory in pages, and when a process discovers that the data it needs to access is not in memory, the operating system may load the data into memory in page form. This process is called page fault, and when a page fault occurs, the operating system will read the page back into memory through a system call.
However, the main memory space is limited. When there is no available space in main memory, the operating system will evict a suitable physical memory page back to disk to make room for the new memory page, the process of selecting the page to evict is called page replacement in the operating system, and the replacement operation will trigger the swap mechanism.
If physical memory is large enough, the Swap mechanism may not be needed, but it still has certain advantages in such cases: for applications (processes) that have a chance of memory leaks, the swap partition is particularly important, as it ensures that memory leaks do not lead to insufficient physical memory, ultimately causing system crashes. However, memory leaks can lead to frequent swapping, which significantly affects the performance of the operating system.
Linux controls the Swap mechanism through a swappiness parameter: this parameter can be set between 0 and 100 to control the priority of swapping in the system:
- High values: Higher frequency of swapping, actively swapping out inactive processes from physical memory.
- Low values: Lower frequency of swapping, ensuring that interactive processes are not frequently swapped to disk, which would increase response latency.
Finally, why is SwapCached also part of Page Cache?
This is because when anonymous pages (Inactive(anon) and Active(anon)) are swapped out to disk and then loaded back into memory, since the original Swap File still exists after being read into memory, SwapCached can also be considered a File-backed page, thus belonging to Page Cache. The process is illustrated in the diagram below.

Page Cache and Buffer Cache#
When executing the free command, you may notice two columns named buffers and cached, as well as a line named "-/+ buffers/cache":
~ free -m
total used free shared buffers cached
Mem: 128956 96440 32515 0 5368 39900
-/+ buffers/cache: 51172 77784
Swap: 16002 0 16001
The cached column indicates the current usage of page cache (Page Cache), while the buffers column indicates the current usage of block cache (buffer cache).
In one sentence: Page Cache is used to cache page data of files, while buffer cache is used to cache block data of block devices (such as disks).
- Pages are a logical concept, so Page Cache is on par with the file system;
- Blocks are a physical concept, so buffer cache is on par with block device drivers.
The common purpose of Page Cache and buffer cache is to accelerate data I/O: - When writing data, it is first written to the cache, marking the written pages as dirty, and then flushing to external storage, which is the write-back mechanism in caching (another method is write-through, which is not used by Linux by default);
- When reading data, it first reads from the cache; if there is a miss, it reads from external storage, and the read data is also added to the cache. The operating system always actively uses all free memory as Page Cache and buffer cache, and when memory is insufficient, it will also use algorithms like LRU to evict cached pages.
In versions of the Linux kernel before 2.4, Page Cache and buffer cache were completely separate. However, since block devices are mostly disks, and the data on disks is mostly organized through file systems, this design led to much data being cached twice, wasting memory.
Thus, after version 2.4 of the kernel, the two caches were merged: if a file's pages are loaded into Page Cache, then the buffer cache only needs to maintain pointers to the blocks pointing to the pages. Only those blocks that do not have file representations or blocks that are directly operated on (like the dd command) will actually be placed in the buffer cache.
Therefore, when we refer to Page Cache now, we basically mean both Page Cache and buffer cache together, and we will no longer distinguish between them in this article, directly referring to them as Page Cache.
The diagram below roughly illustrates a possible structure of Page Cache in a 32-bit Linux system, where the block size is 1KB and the page size is 4KB.

Each file in Page Cache is a radix tree (essentially a multi-way search tree), where each node of the tree is a page. The offset within the file can quickly locate the corresponding page, as shown in the diagram below. For the principles of radix trees, you can refer to the English Wikipedia; it will not be elaborated here.

Page Cache and Read-Ahead#
The operating system provides a read-ahead mechanism (PAGE_READAHEAD) for the read caching mechanism based on Page Cache. An example is:
- The user thread requests to read data from file A on the disk in the range of offset 0-3KB. Since the basic read/write unit of the disk is a block (4KB), the operating system will read at least the content of 0-4KB, which can fit in one page.
- However, due to the principle of locality, the operating system will choose to load the disk blocks offset [4KB,8KB), [8KB,12KB), and [12KB,16KB) into memory as well, thus additionally requesting 3 pages in memory;
The diagram below represents the operating system's read-ahead mechanism:

In the diagram, the application program uses the read system call to read 4KB of data, but the kernel uses the readahead mechanism to complete the reading of 16KB of data.
Page Cache and Consistency & Reliability of File Persistence#
Modern Linux's Page Cache, as its name suggests, is a memory cache for pages (pages) on disk, and can be used for both read and write operations.
Any system that introduces caching will lead to consistency issues: the data in memory may not be consistent with the data on disk. For example, there are consistency issues between Redis cache and MySQL database in common backend architectures.
Linux provides various mechanisms to ensure data consistency, but whether it is the consistency between memory and disk on a single machine or the data consistency issues among nodes 1, 2, and 3 in distributed components, the key to understanding is the trade-off: throughput and data consistency guarantees are contradictory pairs.
First, we need to understand the data of files. File = Data + Metadata. Metadata describes various attributes of the file and must also be stored on disk. Therefore, ensuring file consistency actually includes two aspects: data consistency + metadata consistency.
The metadata of a file includes: file size, creation time, access time, owner, group, and other information.
Let's consider a consistency issue: if a write operation occurs and the corresponding data is in Page Cache, then the write operation will directly affect Page Cache. At this point, if the data has not been flushed to disk, the data in memory will be ahead of that on disk, and the corresponding page will be referred to as a Dirty page.
Currently, Linux implements file consistency in two ways:
- Write Through: Provides specific interfaces to the user layer, allowing applications to actively call interfaces to ensure file consistency;
- Write Back: The system has periodic tasks (in the form of kernel threads) that periodically synchronize dirty data blocks of files in the file system, which is the default consistency scheme in Linux;
Both methods ultimately rely on system calls, mainly divided into the following three system calls:
fsync(fd): Flush all dirty data and metadata of the file represented by fd to disk.
fdatasync(fd): Flush the dirty data of the file represented by fd to disk, along with necessary metadata. The term necessary refers to information that is crucial for subsequent access to the file, such as file size, while file modification time is not considered necessary.
sync(): Flush all dirty file data and metadata in the system to disk.
These three system calls can be initiated by both user processes and kernel processes. Next, let's examine the characteristics of kernel threads.
- The number of kernel threads created for write-back tasks is determined by the persistent storage devices in the system, creating a separate flush thread for each storage device;
- Regarding the architecture of multi-threading, the Linux kernel adopts a model similar to Lighthttp, where there is one management thread and multiple flush threads (each persistent storage device corresponds to one flush thread). The management thread monitors the status of dirty pages on the device; if no dirty pages are generated on the device for a period, it destroys the flush thread on that device; if it detects that there are dirty pages needing to be written back and a flush thread has not yet been created for that device, it creates a flush thread to handle the dirty page write-back. The flush thread's task is relatively monotonous, only responsible for writing back dirty pages from the device to persistent storage devices.
- The design of the flush thread for flushing dirty pages on the device is roughly as follows:
- Each device maintains a linked list of dirty files, which stores the inodes of the dirty files stored on that device. The so-called write-back of dirty pages means writing back the dirty pages of certain files on this inode list;
- There are multiple opportunities for write-back in the system: first, when the application program actively calls write-back interfaces (fsync, fdatasync, sync, etc.); second, the management thread periodically wakes up the flush thread on the device to perform write-back; third, when certain applications/kernel tasks find that memory is insufficient and need to reclaim some cached pages, they perform dirty page write-back in advance. It is essential to design a unified framework to manage these write-back tasks.
Write Through and Write Back differ in terms of persistence reliability:
- Write Through sacrifices system I/O throughput to ensure that once written, the data has been flushed to disk and will not be lost;
- Write Back cannot ensure that data has been flushed to disk in the event of a system crash, thus posing a risk of data loss. However, if a program crashes (e.g., is killed with -9), the operating system will still ensure that the data in Page Cache is flushed to disk;
Advantages and Disadvantages of Page Cache#
Advantages of Page Cache#
1. Accelerates Data Access
If data can be cached in memory, the next access does not need to go through disk I/O, but can directly hit the memory cache.
Since memory access is much faster than disk access, accelerating data access is a significant advantage of Page Cache.
2. Reduces I/O Operations and Increases System Disk I/O Throughput
Thanks to the caching and read-ahead capabilities of Page Cache, and since programs often conform to the principle of locality, loading multiple pages into Page Cache through a single I/O operation can reduce the number of disk I/O operations, thereby increasing the system's disk I/O throughput.
Disadvantages of Page Cache#
Page Cache also has its disadvantages. The most direct drawback is that it requires additional physical memory space. When physical memory is tight, this may lead to frequent swap operations, ultimately increasing the disk I/O load on the system.
Another drawback of Page Cache is that it does not provide a good management API for the application layer; it is almost transparently managed. Even if the application layer wants to optimize the usage strategy of Page Cache, it is difficult to do so. Therefore, some applications choose to implement their own page management in user space instead of using Page Cache, such as the MySQL InnoDB storage engine, which manages pages of 16KB.
The last drawback of Page Cache is that in certain application scenarios, it incurs one additional disk read I/O and disk write I/O compared to Direct I/O.
Direct I/O refers to direct I/O. The term "direct" is used to distinguish it from cached I/O that uses the Page Cache mechanism.
- Cached file I/O: The user space reads and writes a file and does not directly interact with the disk but is interspersed with a layer of cache, namely Page Cache;
- Direct file I/O: The user space reads the file directly from the disk without the intermediate Page Cache layer;
"Direct" here also has another meaning: in all other technologies, data must be stored at least once in kernel space, but in Direct I/O technology, data is stored directly in user space, bypassing the kernel.
The Direct I/O model is illustrated in the diagram below:

At this point, the user space directly copies data to and from the disk and network card via DMA.
Direct I/O has very distinctive read and write characteristics:
- Write operations: Since it does not use Page Cache, if the write file returns successfully, the data is indeed flushed to disk (not considering the disk's own cache);
- Read operations: Since it does not use Page Cache, each read operation is genuinely read from the disk, not from the file system's cache.
Zero-Copy#
The speed of disk read/write is more than ten times slower than that of memory, so there are many technologies for optimizing disks, such as zero-copy, direct I/O, asynchronous I/O, etc. The purpose of these optimizations is to improve system throughput. Additionally, the disk high-speed cache area in the operating system kernel can effectively reduce the number of disk accesses.
What is DMA Technology?#
When transferring data between I/O devices and memory, the data transfer work is entirely handled by the DMA controller, and the CPU no longer participates in any data transfer-related tasks, allowing the CPU to handle other tasks.
The process of using a DMA controller for data transfer is as follows:
The specific process is:
- The user process calls the read method, issuing an I/O request to the operating system to read data into its memory buffer, and the process enters a blocked state;
- After receiving the request, the operating system further sends the I/O request to DMA, allowing the CPU to perform other tasks;
- DMA then sends the I/O request to the disk;
- The disk receives the DMA I/O request and reads the data from the disk into the disk controller's buffer. When the disk controller's buffer is full, it sends an interrupt signal to DMA, notifying that its buffer is full;
- DMA receives the signal from the disk and copies the data from the disk controller's buffer to the kernel buffer, without occupying the CPU, allowing the CPU to execute other tasks;
- When DMA has read enough data, it sends an interrupt signal to the CPU;
- The CPU receives the signal from DMA, knows that the data is ready, and then copies the data from the kernel to user space, returning from the system call;
As we can see, the CPU no longer participates in the work of "moving data from the disk controller's buffer to kernel space"; this part is entirely handled by DMA. However, the CPU is still essential in this process, as it needs to tell the DMA controller what data to transfer and from where to where.
Early DMA existed only on the motherboard, but now, due to the increasing number of I/O devices and varying data transfer needs, each I/O device has its own DMA controller.
How to Optimize File Transfer Performance?#
Traditional file transfers involve 4 context switches between user mode and kernel mode due to two system calls, one for read() and one for write(). Each system call necessitates a switch from user mode to kernel mode and back again after the kernel completes its task.
The cost of context switching is not negligible; each switch can take tens of nanoseconds to several microseconds. Although this time seems short, in high-concurrency scenarios, such time can accumulate and amplify, affecting system performance.
Additionally, there are 4 data copies involved, two of which are DMA copies, and the other two are copies via the CPU.
Therefore, to improve file transfer performance, it is necessary to reduce the number of "context switches between user mode and kernel mode" and "memory copies."
How to reduce the number of "context switches between user mode and kernel mode"?
When reading disk data, context switches occur because user space does not have permission to operate on the disk or network card. Each system call will inevitably involve 2 context switches: first switching from user mode to kernel mode, and then switching back to user mode after the kernel completes its task.
Thus, to reduce the number of context switches, it is essential to minimize the number of system calls.
How to reduce the number of "data copies"?
Traditional file transfer methods undergo 4 data copies, and among these, "copying from the kernel's read buffer to the user's buffer and then from the user's buffer to the socket's buffer" is unnecessary.
In file transfer application scenarios, we do not "reprocess" the data in user space, so the data can actually remain in kernel space without needing to be moved to user space, meaning the user's buffer is unnecessary.
How to Achieve Zero-Copy?#
Zero-copy technology is typically implemented in two ways: mmap + write, sendfile.
mmap + write#
As we learned earlier, the read() system call copies data from the kernel buffer to the user's buffer. To reduce this overhead, we can replace the read() system call with mmap().
The mmap() system call directly "maps" the data in the kernel buffer to user space, so the operating system kernel and user space no longer need to perform any data copy operations.
The specific process is as follows:
- After the application process calls mmap(), DMA copies the data from the disk to the kernel's buffer. Then, the application process "shares" this buffer with the operating system kernel;
- The application process then calls write(), and the operating system directly copies the data from the kernel buffer to the socket buffer, all occurring in kernel mode, with the CPU handling the data transfer;
- Finally, the data in the kernel's socket buffer is copied to the network card's buffer, a process handled by DMA.
We can see that by using mmap() instead of read(), we can reduce one data copy process.
However, this is not the ideal zero-copy solution, as we still need the CPU to copy data from the kernel buffer to the socket buffer, and there are still 4 context switches, as there are still 2 system calls.
sendfile#
In Linux kernel version 2.1, a dedicated system call function for sending files, sendfile(), was introduced. The function signature is as follows:
#include <sys/socket.h>
ssize_t sendfile(int out_fd, int in_fd, off_t *offset, size_t count);
The first two parameters are the destination and source file descriptors, while the last two parameters are the source offset and the length of the data to be copied. The return value is the actual length of the copied data.
First, it can replace the previous read() and write() system calls, thus reducing one system call and consequently reducing 2 context switches.
Secondly, this system call can directly copy data from the kernel buffer to the socket buffer without copying it to user space, resulting in only 2 context switches and 3 data copies. The process is illustrated in the diagram below:
However, this is still not a true zero-copy technology. If the network card supports SG-DMA (The Scatter-Gather Direct Memory Access) technology (which differs from ordinary DMA), we can further reduce the process of copying data from the kernel buffer to the socket buffer.
Thus, starting from Linux kernel version 2.4, the process of the sendfile() system call has changed when the network card supports SG-DMA technology. The specific process is as follows:
- First, DMA copies data from the disk to the kernel buffer;
- Second, the buffer descriptor and data length are passed to the socket buffer, allowing the network card's SG-DMA controller to directly copy data from the kernel cache to the network card's buffer. This process does not require copying data from the operating system's kernel buffer to the socket buffer, thus reducing one data copy;
Therefore, in this process, only 2 data copies occur, as illustrated in the diagram below:
This is what is referred to as zero-copy technology because we do not copy data at the memory level, meaning that all data is transferred via DMA.
The file transfer method using zero-copy technology can reduce the number of context switches and data copies compared to traditional file transfer methods, requiring only 2 context switches and data copies, and both data copy processes are handled by DMA.
Overall, zero-copy technology can improve file transfer performance by at least double.
What Method to Use for Large File Transfers?#
Large file transfers should not use Page Cache, as they may occupy Page Cache and prevent "hot" small files from utilizing Page Cache.
Thus, in high-concurrency scenarios, the method for transferring large files should use "asynchronous I/O + direct I/O" instead of zero-copy technology.
Common scenarios for using direct I/O include:
- The application program has already implemented caching of disk data, so there is no need for Page Cache to cache again, reducing additional performance loss. In MySQL databases, direct I/O can be enabled through parameter settings, which is off by default;
- When transferring large files, since large files are difficult to hit Page Cache and may fill Page Cache, preventing "hot" files from fully utilizing the cache, thus increasing performance overhead, direct I/O should be used.
Additionally, since direct I/O bypasses Page Cache, it cannot benefit from these two optimizations by the kernel:
- The kernel's I/O scheduling algorithm will cache as many I/O requests as possible in Page Cache and finally "merge" them into a larger I/O request to send to the disk, which reduces disk addressing operations;
- The kernel will also "read ahead" subsequent I/O requests into Page Cache, again to reduce disk operations;
Thus, when transferring large files, using "asynchronous I/O + direct I/O" allows for non-blocking file reading.
Therefore, when transferring files, we should use different methods based on the file size:
- For transferring large files, use "asynchronous I/O + direct I/O";
- For transferring small files, use "zero-copy technology";
In nginx, we can use the following configuration to use different methods based on file size:
location /video/ {
sendfile on;
aio on;
directio 1024m;
}
When the file size exceeds the directio value, "asynchronous I/O + direct I/O" is used; otherwise, "zero-copy technology" is used.