1. ファイルシステムの基本構成#
Linux ファイルシステムは、各ファイルに対して 2 つのデータ構造を割り当てます:インデックスノード(index node)とディレクトリエントリ(directory entry)。これらは主にファイルのメタ情報とディレクトリ階層構造を記録するために使用されます。
- インデックスノード、つまり _inode_は、ファイルのメタ情報を記録するために使用されます。例えば、inode 番号、ファイルサイズ、アクセス権、作成時間、変更時間、ディスク上のデータの位置などです。インデックスノードはファイルの唯一の識別子であり、互いに一対一で対応し、同様にハードディスクに保存されるため、インデックスノードもディスクスペースを占有します。
- ディレクトリエントリ、つまり _dentry_は、ファイルの名前、インデックスノードポインタ、および他のディレクトリエントリとの階層的関連を記録するために使用されます。複数のディレクトリエントリが関連付けられると、ディレクトリ構造が形成されますが、インデックスノードとは異なり、ディレクトリエントリはカーネルによって管理されるデータ構造であり、ディスクには保存されず、メモリにキャッシュされます。
インデックスノードはファイルを一意に識別し、ディレクトリエントリはファイルの名前を記録するため、ディレクトリエントリとインデックスノードの関係は多対一です。つまり、1 つのファイルには複数の別名が存在する可能性があります。例えば、ハードリンクの実装は、複数のディレクトリエントリのインデックスノードが同じファイルを指すことによって実現されます。
注意すべきは、ディレクトリもファイルであり、インデックスノードによって一意に識別されることです。通常のファイルとは異なり、通常のファイルはディスクにファイルデータを保存しますが、ディレクトリファイルはディスクにサブディレクトリやファイルを保存します。
ディレクトリエントリとディレクトリは同じものですか?
名前は非常に似ていますが、彼らは同じものではありません。ディレクトリはファイルであり、ディスクに永続的に保存されますが、ディレクトリエントリはカーネルのデータ構造であり、メモリにキャッシュされます。
ディレクトリを頻繁にクエリすると、ディスクからの読み取り効率が非常に低下するため、カーネルは既に読み取ったディレクトリをディレクトリエントリというデータ構造でメモリにキャッシュします。次回同じディレクトリを再度読み取るときは、メモリから読み取るだけで済み、ファイルシステムの効率が大幅に向上します。
注意すべきは、ディレクトリエントリというデータ構造は、ディレクトリを表すだけでなく、ファイルを表すこともできるということです。
では、ファイルデータはどのようにディスクに保存されるのでしょうか?
ディスクの読み書きの最小単位はセクタであり、セクタのサイズはわずか 512B です。明らかに、毎回この小さな単位で読み書きすると、効率が非常に低下します。
そのため、ファイルシステムは複数のセクタを組み合わせて論理ブロックを形成し、毎回の読み書きの最小単位は論理ブロック(データブロック)になります。Linux における論理ブロックのサイズは 4KB であり、つまり一度に 8 つのセクタを読み書きすることができ、これによりディスクの読み書き効率が大幅に向上します。
以上がインデックスノード、ディレクトリエントリ、およびファイルデータの関係です。以下の図は、彼らの関係をよく示しています:

インデックスノードはハードディスク上に保存されるデータですが、ファイルへのアクセスを加速するために、通常はインデックスノードをメモリにロードします。
さらに、ディスクがフォーマットされるとき、3 つのストレージ領域に分割されます:スーパーブロック、インデックスノード領域、およびデータブロック領域。
- _スーパーブロック_は、ファイルシステムの詳細情報を保存するために使用されます。例えば、ブロックの数、ブロックサイズ、空きブロックなどです。
- _インデックスノード領域_は、インデックスノードを保存するために使用されます;
- _データブロック領域_は、ファイルまたはディレクトリデータを保存するために使用されます;
スーパーブロックとインデックスノード領域をすべてメモリにロードすることは不可能であり、メモリが確実に持たないため、必要なときにのみメモリにロードされます。これらがメモリにロードされるタイミングは異なります:
- スーパーブロック:ファイルシステムがマウントされるときにメモリに入ります;
- インデックスノード領域:ファイルがアクセスされるときにメモリに入ります;
2. 仮想ファイルシステム#
ファイルシステムの種類は多岐にわたり、オペレーティングシステムはユーザーに統一されたインターフェースを提供したいと考えています。そのため、ユーザーレイヤーとファイルシステムレイヤーの間に中間層を導入しました。この中間層は ** 仮想ファイルシステム(Virtual File System, VFS)** と呼ばれます。
VFS は、すべてのファイルシステムがサポートするデータ構造と標準インターフェースのセットを定義しており、プログラマーはファイルシステムの動作原理を理解する必要はなく、VFS が提供する統一インターフェースを理解するだけで済みます。
Linux ファイルシステムでは、ユーザースペース、システムコール、仮想ファイルシステム、キャッシュ、ファイルシステム、およびストレージ間の関係は以下の図のようになります:
Linux がサポートするファイルシステムも多く、ストレージ位置の違いに応じて、ファイルシステムは 3 つのカテゴリに分けることができます:
- _ディスクファイルシステム_は、データをディスクに直接保存します。例えば、Ext 2/3/4、XFS などがこのタイプのファイルシステムです。
- _メモリファイルシステム_は、このタイプのファイルシステムのデータはハードディスクに保存されず、メモリスペースを占有します。私たちがよく使用する
/procや/sysファイルシステムはこのカテゴリに属し、これらのファイルを読み書きすることは、実際にはカーネル内の関連データを読み書きすることです。 - _ネットワークファイルシステム_は、他のコンピュータホストのデータにアクセスするためのファイルシステムです。例えば、NFS、SMB などです。
ファイルシステムは、特定のディレクトリにマウントされて初めて正常に使用できます。例えば、Linux システムは起動時にファイルシステムをルートディレクトリにマウントします。
3. ファイルの使用#
ユーザーの視点から見ると、ファイルをどのように使用するかが重要です。まず、システムコールを通じてファイルを開く必要があります。

ファイルを読み取る過程:
- まず、
openシステムコールを使用してファイルを開きます。openのパラメータにはファイルのパス名とファイル名が含まれます。 writeを使用してデータを書き込みます。このとき、writeはopenが返したファイルディスクリプタを使用し、ファイル名をパラメータとして使用しません。- ファイルの使用が終わったら、
closeシステムコールを使用してファイルを閉じ、リソースの漏洩を避けます。
ファイルを開くと、オペレーティングシステムはプロセスが開いたすべてのファイルを追跡します。追跡とは、オペレーティングシステムが各プロセスのオープンファイルテーブルを維持することを意味します。ファイルテーブルの各項目は「ファイルディスクリプタ」を表します。したがって、ファイルディスクリプタはオープンファイルの識別子です。
オペレーティングシステムはオープンファイルテーブル内でオープンファイルの状態と情報を維持しています:
- ファイルポインタ:システムは前回の読み書き位置を追跡し、現在のファイル位置ポインタとして使用します。このポインタはオープンファイルの特定のプロセスにとって一意です;
- ファイルオープンカウンタ:ファイルが閉じられるとき、オペレーティングシステムはそのオープンファイルテーブルのエントリを再利用する必要があります。そうしないと、テーブル内のスペースが不足します。複数のプロセスが同じファイルを開く可能性があるため、システムはオープンファイルエントリを削除する前に、最後のプロセスがファイルを閉じるのを待つ必要があります。このカウンタはオープンとクローズの数を追跡し、カウントが 0 になると、システムはファイルを閉じ、そのエントリを削除します;
- ファイルディスク位置:ほとんどのファイル操作は、システムがファイルデータを変更することを要求します。この情報はメモリに保存され、各操作がディスクから読み取られないようにします;
- アクセス権:各プロセスがファイルを開くには、アクセスモード(作成、読み取り専用、読み書き、追加など)が必要であり、この情報はプロセスのオープンファイルテーブルに保存され、オペレーティングシステムが後続の I/O リクエストを許可または拒否できるようにします;
ユーザーの視点では、ファイルは永続的なデータ構造ですが、オペレーティングシステムはディスク上に存在するデータ構造を気にしません。オペレーティングシステムの視点は、ファイルデータとディスクブロックをどのように対応させるかです。
したがって、ユーザーとオペレーティングシステムのファイルの読み書き操作には違いがあります。ユーザーはバイト単位でファイルを読み書きすることに慣れていますが、オペレーティングシステムはデータブロック単位でファイルを読み書きします。この差異を隠す作業がファイルシステムです。
ファイルを読み書きする過程を見てみましょう:
- ユーザープロセスがファイルから 1 バイトのデータを読み取ると、ファイルシステムはバイトが存在するデータブロックを取得し、データブロックに対応するユーザープロセスが必要とするデータ部分を返します。
- ユーザープロセスが 1 バイトのデータをファイルに書き込むと、ファイルシステムは書き込むデータのデータブロックの位置を見つけ、データブロック内の対応部分を変更し、最後にデータブロックをディスクに書き戻します。
つまり、ファイルシステムの基本操作単位はデータブロックです。
4. ファイルの保存#
1. 連続スペース保存方式#
連続スペース保存方式はその名の通り、ファイルはディスクの「連続した」物理スペースに保存されます。このモードでは、ファイルのデータは密接に接続されており、読み書き効率が非常に高いです。なぜなら、一度のディスクシークでファイル全体を読み出すことができるからです。
連続保存方式を使用するためには、ファイルのサイズを事前に知っておく必要があります。そうすれば、ファイルシステムはファイルのサイズに基づいてディスク上の連続したスペースを見つけてファイルに割り当てることができます。
したがって、ファイルヘッダーには「開始ブロックの位置」と「長さ」を指定する必要があります。これら 2 つの情報があれば、ファイルの保存方式が連続したディスクスペースであることを適切に表現できます。
注意すべきは、ここで言うファイルヘッダーは、Linux の inode に似ています。

連続スペース保存方式は読み書き効率が高いですが、「ディスクスペースの断片化」と「ファイルの長さの拡張が難しい」という欠点があります。
2. 非連続スペース保存方式#
リンクリスト方式#
リンクリスト方式は離散的で、連続的ではありません。したがって、ディスクの断片化を解消することができ、ディスクスペースの利用率を大幅に向上させることができます。また、ファイルの長さを動的に拡張することができます。
暗黙のリンクリスト
実装方法は、ファイルヘッダーに「最初のブロック」と「最後のブロック」の位置を含め、各データブロック内に次のデータブロックの位置を保存するためのポインタスペースを残します。こうして、1 つのデータブロックが次のデータブロックに連結され、リンクの先頭から始めてポインタに沿ってすべてのデータブロックを見つけることができます。したがって、保存方式は非連続的である可能性があります。

暗黙のリンクリストの保存方式の欠点は、データブロックに直接アクセスできず、ポインタを介して順番にファイルにアクセスする必要があることです。また、データブロックのポインタは一定のストレージスペースを消費します **。暗黙のリンクの割り当ての安定性は低く、システムが実行中にソフトウェアまたはハードウェアのエラーによりリンクリスト内のポインタが失われたり損傷したりすると、ファイルデータが失われる可能性があります。
明示的リンク
これはファイルの各データブロックをリンクするためのポインタを、メモリ内のリンクテーブルに明示的に保存することを指します。このテーブルはディスク全体に 1 つだけ設定され、各テーブル項目にはリンクポインタが保存され、次のデータブロック番号を指します。
明示的リンクの作業方式の例として、ファイル A がディスクブロック 4、7、2、10、12 を順次使用し、ファイル B がディスクブロック 6、3、11、14 を順次使用したとします。下の図のテーブルを利用して、4 ブロックから始めて、リンクに沿って最後まで進むことで、ファイル A のすべてのディスクブロックを見つけることができます。同様に、6 ブロックから始めて、リンクに沿って最後まで進むことで、ファイル B のすべてのディスクブロックを見つけることができます。最後に、これらの 2 つのリンクは、有効なディスク番号に属さない特殊なマーク(例えば - 1)で終了します。メモリ内のこのようなテーブルは ** ファイル割り当てテーブル(File Allocation Table, FAT)** と呼ばれます。

記録の検索プロセスがメモリ内で行われるため、検索速度が大幅に向上し、ディスクへのアクセス回数が大幅に減少します。しかし、テーブル全体がメモリに保存されるため、主な欠点は大きなディスクには適用できないことです。
例えば、200GB のディスクと 1KB のブロックサイズの場合、このテーブルには 2 億項目が必要であり、それぞれの項目はこの 2 億のディスクブロックの 1 つに対応します。各項目が 4 バイトを必要とする場合、このテーブルは 800MB のメモリを占有します。明らかに、FAT ソリューションは大きなディスクには適していません。
インデックス方式#
インデックスの実装は、各ファイルに「インデックスデータブロック」を作成し、そこにファイルデータブロックへのポインタリストを保存します。言い換えれば、これは本の目次のようなもので、どの章の内容を探すかは目次を参照すればわかります。
さらに、ファイルヘッダーには「インデックスデータブロック」へのポインタが含まれる必要があります。これにより、ファイルヘッダーからインデックスデータブロックの位置を知り、インデックスデータブロック内のインデックス情報を介して対応するデータブロックを見つけることができます。
ファイルを作成するとき、インデックスブロックのすべてのポインタは空に設定されます。最初に i ブロックに書き込むとき、空きスペースからブロックを取得し、そのアドレスをインデックスブロックの i 番目の項目に書き込みます。

インデックス方式の利点は:
- ファイルの作成、拡大、縮小が非常に便利です;
- 断片化の問題が発生しません;
- 順次読み書きとランダム読み書きをサポートします;
インデックスデータもディスクブロックに保存されるため、ファイルが非常に小さい場合、明らかに 1 つのブロックで保存できるにもかかわらず、インデックスデータを保存するために追加のブロックを割り当てる必要があるため、欠点の 1 つはインデックス保存によるオーバーヘッドです。
リンクインデックスブロック
ファイルが非常に大きい場合、1 つのインデックスデータブロックにインデックス情報を収めることができない場合、どのように大ファイルを保存するかを考えます。私たちは組み合わせの方法を使用して、大ファイルを保存することができます。
まず、リンクリスト + インデックスの組み合わせを見てみましょう。この組み合わせは「リンクインデックスブロック」と呼ばれ、実装方法はインデックスデータブロックに次のインデックスデータブロックのポインタを保存するためのスペースを残します。したがって、インデックスデータブロックのインデックス情報が使い果たされると、ポインタの方法で次のインデックスデータブロックの情報を見つけることができます。この方法は、前述のリンクリスト方式の問題が発生する可能性があります。万が一、あるポインタが損傷した場合、後続のデータも読み取れなくなります。

もう 1 つの組み合わせ方式はインデックス + インデックスの方法であり、この組み合わせは「多段階インデックスブロック」と呼ばれ、実装方法は1 つのインデックスブロックに複数のインデックスデータブロックを保存することです。これは、層を重ねたインデックスのようで、ロシアのマトリョーシカのようです。

3.Unix ファイルの実装方式#
ファイルのサイズに応じて、保存方式が異なります:
- ファイルに必要なデータブロックが 10 ブロック未満の場合、直接検索方式を採用します;
- ファイルに必要なデータブロックが 10 ブロックを超える場合、一次間接インデックス方式を採用します;
- 前述の 2 つの方式では大ファイルを保存するには不十分な場合、二次間接インデックス方式を採用します;
- 二次間接インデックスでも大ファイルを保存するには不十分な場合、三次間接インデックス方式を採用します;
したがって、ファイルヘッダー(Inode)には 13 のポインタが含まれる必要があります:
- 10 個のデータブロックを指すポインタ;
- 11 番目はインデックスブロックを指すポインタ;
- 12 番目は二次インデックスブロックを指すポインタ;
- 13 番目は三次インデックスブロックを指すポインタ;
この方法は、小ファイルと大ファイルの保存を柔軟にサポートできます:
- 小ファイルには直接検索方式を使用してインデックスデータブロックのオーバーヘッドを削減できます;
- 大ファイルには多段階インデックス方式を使用してサポートします。したがって、大ファイルのデータブロックにアクセスするには多くのクエリが必要です。
4. 空きスペース管理#
データブロックを保存するために、ハードディスク上のどの位置に置くべきでしょうか?すべてのブロックをスキャンして空いている場所を見つける必要があるのでしょうか?
そのような方法では効率が非常に低下します。したがって、ディスクの空きスペースに対しても管理メカニズムを導入する必要があります。次に、いくつかの一般的な方法を紹介します:
- 空きテーブル法
- 空きリンクリスト法
- ビットマップ法
空きテーブル法#
空きテーブル法は、すべての空きスペースのためにテーブルを作成し、テーブルの内容には空き領域の最初のブロック番号とその空き領域のブロック数が含まれます。この方法は連続割り当てです。以下の図のように:

ディスクスペースの割り当てを要求すると、システムは空きテーブルの内容を順次スキャンし、適切な空き領域を見つけるまで続けます。ユーザーがファイルを取り消すと、システムはファイルスペースを回収します。このとき、空きテーブルを順次スキャンし、空きテーブルのエントリを見つけ、解放されたスペースの最初の物理ブロック番号とその占有ブロック数をこのエントリに記入する必要があります。
この方法は、空き領域が少ない場合にのみ良好な効果を発揮します。なぜなら、ストレージスペースに多数の小さな空き領域がある場合、空きテーブルが非常に大きくなり、検索効率が低下するからです。また、この分配技術は連続ファイルの構築に適しています。
空きリンクリスト法#
「リンクリスト」の方式を使用して空きスペースを管理することもできます。各空きブロックには次の空きブロックを指すポインタがあり、これにより空きブロックを簡単に見つけて管理できます。以下の図のように:

ファイルを作成する際に 1 つまたは数ブロックが必要な場合、リンクの先頭から順次 1 つまたは数ブロックを取得します。逆に、スペースを回収する際には、これらの空きブロックを順次リンクの先頭に接続します。
この技術は、主記憶内に 1 つのポインタを保存し、最初の空きブロックを指すようにします。その特徴はシンプルですが、ランダムアクセスができず、作業効率が低下します。なぜなら、リンクに空きブロックを追加または移動するたびに多くの I/O 操作を行う必要があり、データブロックのポインタが一定のストレージスペースを消費するからです。
空きテーブル法と空きリンクリスト法は、大型ファイルシステムには適していません。なぜなら、空きテーブルまたは空きリンクリストが非常に大きくなってしまうからです。
ビットマップ法#
ビットマップは、ディスク上の各ブロックの使用状況を示すために、2 進数の 1 ビットを利用します。ディスク上のすべてのブロックには、対応する 2 進数のビットがあります。
値が 0 の場合、対応するブロックは空いていることを示し、値が 1 の場合、対応するブロックは割り当てられていることを示します。形式は次のようになります:
1111110011111110001110110111111100111 ...
Linux ファイルシステムでは、ビットマップ方式を使用して空きスペースを管理しており、データ空きブロックの管理だけでなく、inode 空きブロックの管理にも使用されます。なぜなら、inode もディスクに保存されているため、当然管理が必要です。
5. ファイルシステムの構造#
ユーザーが新しいファイルを作成すると、Linux カーネルは inode のビットマップを通じて空いている inode を見つけて割り当てます。データを保存する際には、ブロックのビットマップを通じて空いているブロックを見つけて割り当てますが、注意深く計算すると、まだ問題があります。
データブロックのビットマップはディスクブロックに保存されており、仮定として 1 つのブロックに保存されているとします。1 つのブロックは 4K であり、各ビットは 1 つのデータブロックを表します。合計で 4 * 1024 * 8 = 2^15 個の空きブロックを表すことができます。1 つのデータブロックは 4K のサイズであるため、最大で表現できるスペースは 2^15 * 4 * 1024 = 2^27 バイト、つまり 128M です。
つまり、上記の構造に従うと、「1 つのブロックのビットマップ + 一連のブロック」、さらに「1 つのブロックの inode のビットマップ + 一連の inode の構造」で表現できる最大スペースは 128M に過ぎず、これは非常に少ないです。現在、多くのファイルはこれよりも大きいです。
Linux ファイルシステムでは、この構造をブロックグループと呼びます。N 個のブロックグループがあれば、N 大のファイルを表現できます。
以下の図は、Linux Ext2 全体のファイルシステムの構造とブロックグループの内容を示しています。ファイルシステムは大量のブロックグループで構成され、ハードディスク上に順次配置されています:

最初のブロックはブートブロックであり、システム起動時にブートを有効にするために使用され、その後は連続したブロックグループが続きます。ブロックグループの内容は次のとおりです:
- _スーパーブロック_は、ファイルシステムの重要な情報を含みます。例えば、inode の総数、ブロックの総数、各ブロックグループの inode の数、各ブロックグループのブロックの数などです。
- _ブロックグループ記述子_は、ファイルシステム内の各ブロックグループの状態を含みます。例えば、ブロックグループ内の空きブロックと inode の数などです。各ブロックグループには、ファイルシステム内の「すべてのブロックグループのグループ記述子情報」が含まれています。
- _データビットマップと inode ビットマップ_は、対応するデータブロックまたは inode が空いているか、使用中であるかを示します。
- _inode リスト_は、ブロックグループ内のすべての inode を含み、inode はファイルシステム内の各ファイルおよびディレクトリに関連するすべてのメタデータを保存するために使用されます。
- _データブロック_は、ファイルの有用なデータを含みます。
各ブロックグループには多くの重複情報があることに気付くかもしれません。例えば、スーパーブロックとブロックグループ記述子テーブルは、どちらもグローバル情報であり、非常に重要です。これには 2 つの理由があります: - システムがクラッシュしてスーパーブロックまたはブロックグループ記述子が破損すると、ファイルシステムの構造と内容に関するすべての情報が失われます。冗長なコピーがあれば、その情報は復元可能です。
- ファイルと管理データをできるだけ近くに配置することで、ヘッドのシークと回転を減らし、ファイルシステムのパフォーマンスを向上させることができます。
ただし、Ext2 の後続バージョンではスパース技術が採用されました。この方法では、スーパーブロックとブロックグループ記述子テーブルは、ファイルシステムの各ブロックグループに保存されるのではなく、ブロックグループ 0、ブロックグループ 1、および他の ID が 3、5、7 の累乗として表されるブロックグループにのみ書き込まれます。
6. ディレクトリの保存#
通常のファイルのブロックにはファイルデータが保存されますが、ディレクトリファイルのブロックにはディレクトリ内の各ファイル情報が保存されます。
ディレクトリファイルのブロック内で最も単純な保存形式はリストであり、ディレクトリ内のファイル情報(ファイル名、ファイル inode、ファイルタイプなど)を項目ごとにリストにします。
リストの各項目は、そのディレクトリ内のファイル名と対応する inode を表します。この inode を介して、実際のファイルを見つけることができます。

通常、最初の項目は「.」で、現在のディレクトリを示し、2 番目の項目は「..」で、上位ディレクトリを示します。その後は、項目ごとのファイル名と inode が続きます。
もしディレクトリに非常に多くのファイルがある場合、そのディレクトリ内でファイルを探すには、リストを項目ごとに探すのは効率が良くありません。
したがって、ディレクトリの保存形式はハッシュテーブルに変更され、ファイル名にハッシュ計算を行い、ハッシュ値を保存します。ディレクトリ内のファイル名を検索する場合、名前を使用してハッシュを取得できます。ハッシュが一致すれば、そのファイルの情報が対応するブロック内にあることがわかります。
Linux システムの ext ファイルシステムは、ディレクトリの内容を保存するためにハッシュテーブルを採用しています。この方法の利点は、検索が非常に迅速で、挿入と削除も比較的簡単ですが、ハッシュ衝突を回避するためのいくつかの準備措置が必要です。
ディレクトリのクエリは、ディスク上で繰り返し検索を行うことで完了し、I/O 操作を継続的に行う必要があるため、コストが高くなります。したがって、I/O 操作を減らすために、現在使用しているファイルのディレクトリをメモリにキャッシュし、後でそのファイルを使用する際にはメモリ内で操作するだけで済むようにし、ディスク操作の回数を減らし、ファイルシステムのアクセス速度を向上させます。
7. ハードリンクとソフトリンク#
時々、特定のファイルに別名を付けたい場合があります。そのため、Linux では ** ハードリンク(Hard Link)とソフトリンク(Symbolic Link)** の方法を使用して実現できます。これらは特別なファイルですが、実装方法は異なります。
ハードリンク#
ハードリンクは複数のディレクトリエントリの「インデックスノード」が 1 つのファイルを指すことを意味します。つまり、同じ inode を指しますが、inode はファイルシステムを越えて存在することはできません。各ファイルシステムには独自の inode データ構造とリストがあるため、ハードリンクはファイルシステムを越えて使用することはできません。複数のディレクトリエントリが同じ inode を指すため、ファイルのすべてのハードリンクと元のファイルを削除したときにのみ、システムはそのファイルを完全に削除します。

ソフトリンク#
ソフトリンクは、別のファイルのパスを持つ独立した inodeを持つファイルを再作成することに相当します。したがって、ソフトリンクにアクセスすると、実際には別のファイルにアクセスすることになります。したがって、ソフトリンクはファイルシステムを越えて使用することができ、ターゲットファイルが削除されても、リンクファイルは存在しますが、指し示すファイルが見つからなくなります。

8. ファイル I/O#
ファイルの読み書き方式はそれぞれ異なり、ファイルの I/O 分類も非常に多く、一般的なものには次のようなものがあります:
- バッファ I/O と非バッファ I/O
- 直接 I/O と非直接 I/O
- ブロッキング I/O と非ブロッキング I/O VS 同期 I/O と非同期 I/O
バッファ I/O と非バッファ I/O#
ファイル操作の標準ライブラリはデータのキャッシュを実現できます。したがって、「標準ライブラリのバッファを利用するかどうか」に基づいて、ファイル I/O はバッファ I/O と非バッファ I/O に分けることができます:
- バッファ I/O は、標準ライブラリのキャッシュを利用してファイルの高速アクセスを実現し、標準ライブラリはシステムコールを介してファイルにアクセスします。
- 非バッファ I/O は、システムコールを介して直接ファイルにアクセスし、標準ライブラリのキャッシュを経由しません。
ここで言う「バッファ」は、標準ライブラリ内部で実装されたバッファを特に指します。
例えば、多くのプログラムは改行時にのみ実際に出力され、改行前の内容は標準ライブラリに一時的にキャッシュされています。これにより、システムコールの回数を減らすことができます。システムコールには CPU のコンテキストスイッチのオーバーヘッドがあるためです。
直接 I/O と非直接 I/O#
私たちは、ディスク I/O が非常に遅いことを知っています。したがって、Linux カーネルはディスク I/O の回数を減らすために、システムコールの後にユーザーデータをカーネルのキャッシュにコピーします。このカーネルキャッシュスペースは「ページキャッシュ」と呼ばれ、キャッシュが特定の条件を満たすときにのみディスク I/O のリクエストが発生します。
したがって、「オペレーティングシステムのキャッシュを利用するかどうか」に基づいて、ファイル I/O は直接 I/O と非直接 I/O に分けることができます:
- 直接 I/O は、カーネルキャッシュとユーザープログラム間でデータのコピーが発生せず、ファイルシステムを介してディスクにアクセスします。
- 非直接 I/O では、読み取り操作中にデータがカーネルキャッシュからユーザープログラムにコピーされ、書き込み操作中にはデータがユーザープログラムからカーネルキャッシュにコピーされ、カーネルがデータをディスクに書き込むタイミングを決定します。
ファイル操作系のシステムコール関数を使用する際に、O_DIRECTフラグを指定すると、直接 I/O を使用することを示します。設定がなければ、デフォルトでは非直接 I/O が使用されます。
非直接 I/O を使用してデータ操作を行った場合、カーネルはどのような状況でキャッシュデータをディスクに書き込むのでしょうか?
以下のような状況で、カーネルキャッシュのデータがディスクに書き込まれます:
writeの最後に、カーネルキャッシュのデータが多すぎることが判明した場合、カーネルはデータをディスクに書き込みます;- ユーザーが
syncを手動で呼び出すと、カーネルキャッシュがディスクにフラッシュされます; - メモリが非常に逼迫しており、ページを再割り当てできない場合、カーネルキャッシュのデータがディスクにフラッシュされます;
- カーネルキャッシュのデータのキャッシュ時間が特定の時間を超えた場合、データがディスクにフラッシュされます;
ブロッキング I/O と非ブロッキング I/O VS 同期 I/O と非同期 I/O#
なぜブロッキング / 非ブロッキングと同期 / 非同期を一緒に説明するのでしょうか?それは、彼らが非常に似ており、混同しやすいからです。しかし、彼らの関係は微妙に異なります。
まず、ブロッキング I/Oを見てみましょう。ユーザープログラムがreadを実行すると、スレッドはブロックされ、カーネルデータが準備できるまで待機し、データがカーネルバッファからアプリケーションのバッファにコピーされるのを待ちます。コピーが完了すると、readが返されます。
注意すべきは、ブロッキングは「カーネルデータが準備できる」および「データがカーネル状態からユーザー状態にコピーされる」この 2 つのプロセスを待っていることです。プロセスは以下の図のようになります:

ブロッキング I/O を理解したら、非ブロッキング I/Oを見てみましょう。非ブロッキングの read リクエストは、データが準備できていない場合に即座に返され、処理を続行できます。このとき、アプリケーションはカーネルをポーリングし続け、データが準備できるまで待機します。カーネルがデータをアプリケーションのバッファにコピーすると、read呼び出しが結果を取得できます。プロセスは以下の図のようになります:
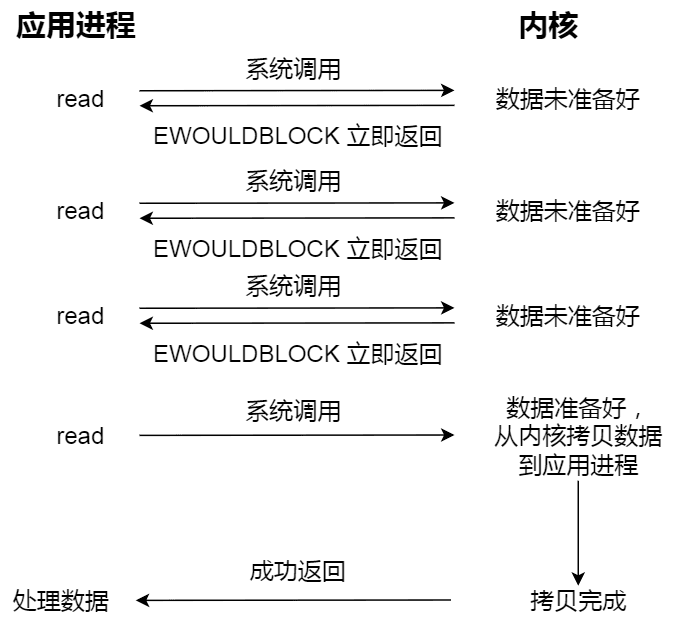
注意すべきは、最後の read 呼び出しでデータを取得するプロセスは同期プロセスであり、待機が必要なプロセスであることです。ここでの同期は、カーネル状態からユーザープログラムのキャッシュにデータをコピーするプロセスを指します。
例えば、パイプやソケットにアクセスする際、O_NONBLOCKフラグを設定すると、非ブロッキング I/O 方式でアクセスすることを示します。何も設定しない場合、デフォルトはブロッキング I/O です。
アプリケーションがカーネルの I/O が準備できているかどうかを毎回ポーリングするのは少し無駄に感じます。ポーリングの間、アプリケーションは何もできず、ただループしているだけです。
このような無駄なポーリング方式を解決するために、I/O 多重化技術が登場しました。例えば、select や poll などです。これは、I/O イベントを分配し、カーネルデータが準備できたときに、イベントを通知してアプリケーションが操作を行うようにします。
この方法は、CPU の利用率を大幅に改善します。なぜなら、I/O 多重化インターフェースを呼び出すと、イベントが発生しない場合、現在のスレッドはブロックされ、CPU は他のスレッドにタスクを実行させることができるからです。カーネルがイベントの到来を検出すると、I/O 多重化インターフェースでブロックされているスレッドを起こし、ユーザーはその後のイベント処理を行うことができます。
全体のプロセスは、ブロッキング I/O よりも複雑で、パフォーマンスを浪費しているように見えます。しかし、I/O 多重化インターフェースの最大の利点は、ユーザーが 1 つのスレッド内で同時に複数のソケットの I/O リクエストを処理できることです(参照:I/O 多重化:select/poll/epoll (opens new window))。ユーザーは複数のソケットを登録し、アクティブなソケットを読み取るために I/O 多重化インターフェースを呼び出し続けることで、同じスレッド内で複数の I/O リクエストを同時に処理することができます。一方、同期ブロッキングモデルでは、これを達成するにはマルチスレッド方式を使用する必要があります。
以下の図は、select I/O 多重化プロセスを示しています。注意すべきは、readでデータを取得するプロセス(データがカーネル状態からユーザー状態にコピーされるプロセス)も同期プロセスであり、待機が必要なプロセスであることです:
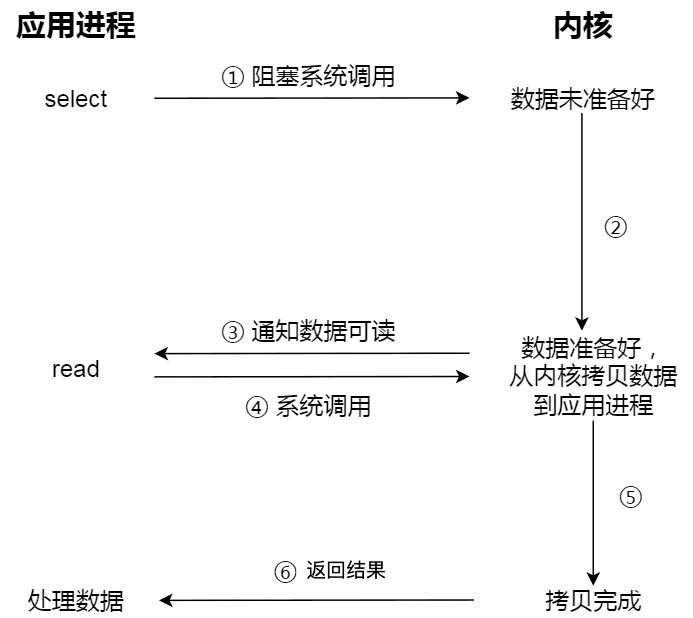
実際には、ブロッキング I/O、非ブロッキング I/O、または非ブロッキング I/O に基づく多重化はすべて同期呼び出しです。なぜなら、これらはread呼び出し時に、カーネルがデータをカーネル空間からアプリケーション空間にコピーするため、プロセスが待機する必要があるからです。つまり、このプロセスは同期的であり、カーネルの実装されたコピー効率が高くない場合、read呼び出しはこの同期プロセスで比較的長い時間待機することになります。
真の非同期 I/Oは、「カーネルデータが準備できる」および「データがカーネル状態からユーザー状態にコピーされる」この 2 つのプロセスを待つ必要がありません。
aio_readを発行すると、すぐに戻り、カーネルは自動的にデータをカーネル空間からアプリケーション空間にコピーします。このコピー過程は非同期であり、カーネルが自動的に完了します。前述の同期操作とは異なり、アプリケーションは積極的にコピーアクションを発起する必要はありません。プロセスは以下の図のようになります:

以下の図は、上記の I/O モデルをまとめたものです:
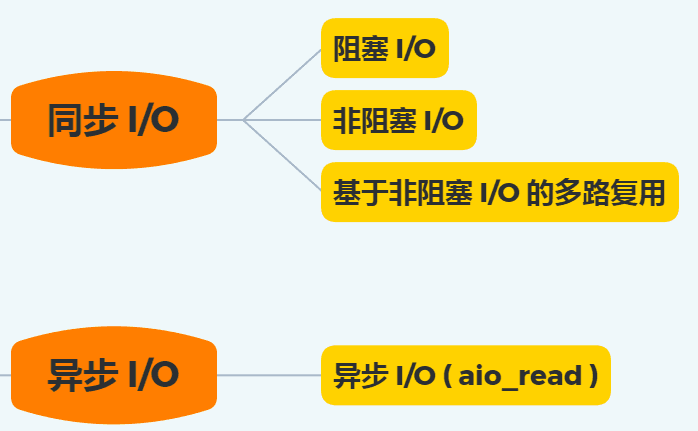
前述のように、I/O は 2 つのプロセスに分かれます:
- データ準備プロセス
- データがカーネル空間からユーザープロセスのバッファにコピーされるプロセス
ブロッキング I/O は「プロセス 1」と「プロセス 2」の両方でブロックされ、非ブロッキング I/O と非ブロッキング I/O に基づく多重化は「プロセス 2」のみでブロックされるため、これらの 3 つはすべて同期 I/O と見なすことができます。
非同期 I/O は異なり、「プロセス 1」と「プロセス 2」の両方でブロックされません。
9. ページキャッシュ#
ページキャッシュとは?#
ページキャッシュを理解するために、Linux のファイル I/O システムを見てみましょう。以下の図のように:

上の図で赤い部分がページキャッシュです。ページキャッシュの本質は、Linux カーネルが管理するメモリ領域です。mmap やバッファ I/O を介してファイルをメモリ空間に読み込むと、実際にはページキャッシュに読み込まれます。
システムのページキャッシュを確認する方法#
/proc/meminfoファイルを読み取ることで、システムのメモリ状況をリアルタイムで取得できます:
$ cat /proc/meminfo
...
Buffers: 1224 kB
Cached: 111472 kB
SwapCached: 36364 kB
Active: 6224232 kB
Inactive: 979432 kB
Active(anon): 6173036 kB
Inactive(anon): 927932 kB
Active(file): 51196 kB
Inactive(file): 51500 kB
...
Shmem: 10000 kB
...
SReclaimable: 43532 kB
...
上記のデータに基づいて、次のような公式(等式の両辺の合計は 112696 KB)を簡単に導き出すことができます:
Buffers + Cached + SwapCached = Active(file) + Inactive(file) + Shmem + SwapCached
両辺の等式はページキャッシュであり、つまり:
ページキャッシュ = Buffers + Cached + SwapCached
以下の小節を読むことで、なぜ SwapCached と Buffers もページキャッシュの一部であるかを理解できます。
ページとページキャッシュ#
ページはメモリ管理で割り当てられる基本単位であり、ページキャッシュは複数のページで構成されています。ページはオペレーティングシステムで通常 4KB のサイズ(32 ビット / 64 ビット)であり、ページキャッシュのサイズは 4KB の整数倍です。
一方、すべてのページがページキャッシュに組織されているわけではありません。
Linux システム上でユーザーがアクセスできるメモリは 2 つのタイプに分かれます:
- ファイルバックページ:ファイルバックページはページキャッシュ内のページであり、ディスク上のいくつかのデータブロックに対応します。これらのページの最大の問題は、ダーティページの回収です;
- 匿名ページ:匿名ページはディスク上のいかなるデータブロックにも対応せず、プロセスの実行時のメモリ空間(例えば、メソッドスタック、ローカル変数テーブルなどの属性)です;
なぜ Linux はページキャッシュをブロックキャッシュとは呼ばないのでしょうか?それはより良いのではないでしょうか?
これは、ディスクからメモリに読み込まれるデータがページキャッシュだけでなく、バッファキャッシュにも保存されるためです。
例えば、Direct I/O 技術を使用したディスクファイルはページキャッシュに入ることはありません。この問題には Linux の歴史的な設計の理由もあります。結局のところ、これは単なる呼称であり、意味は Linux システムの進化とともに徐々に異なります。
以下に、ファイルバックページと匿名ページのスワップメカニズム下でのパフォーマンスを比較します。
メモリは貴重なリソースであり、メモリが不足している場合、メモリ管理ユニット(Memory Management Unit)は関連するメモリ空間を回収するためのスケジューリングアルゴリズムを提供する必要があります。メモリ空間の回収方法は通常スワップ、つまり永続的なストレージデバイスに交換することです。
スワップメカニズムが存在する本質的な理由は、Linux システムが仮想メモリ管理メカニズムを提供しているためです。各プロセスは独占的なメモリ空間を持っていると考えられ、すべてのプロセスのメモリ空間の合計は物理メモリをはるかに超えます。すべてのプロセスのメモリ空間の合計が物理メモリを超える部分は、ディスクにスワップする必要があります。
オペレーティングシステムはページ単位でメモリを管理し、プロセスが必要なデータにアクセスできない場合、オペレーティングシステムはデータをページの形でメモリにロードする可能性があります。このプロセスはページフォールトと呼ばれ、オペレーティングシステムがページフォールトを発生させると、システムコールを介してページを再度メモリに読み込むことになります。
しかし、主メモリの空間は限られています。主メモリに使用可能な空間が含まれていない場合、オペレーティングシステムはディスクに追い出すために適切な物理メモリページを選択し、新しいメモリページに位置を空けます。追い出すページの選択プロセスはオペレーティングシステム内でページ置換(Page Replacement)と呼ばれ、置換操作はスワップメカニズムを引き起こします。
物理メモリが十分に大きい場合、スワップメカニズムは必要ないかもしれませんが、スワップはこの場合でも一定の利点があります。メモリリークの可能性があるアプリケーション(プロセス)にとって、スワップパーティションは非常に重要です。これにより、メモリリークが物理メモリ不足を引き起こし、最終的にシステムがクラッシュするのを防ぐことができます。しかし、メモリリークは頻繁なスワップを引き起こし、この場合、オペレーティングシステムのパフォーマンスに非常に影響を与えます。
Linux はスワップメカニズムを制御するために、スワップネスパラメータを提供します。このパラメータの値は 0 から 100 までで、システムのスワップの優先度を制御します:
- 高い値:スワップの頻度が高く、プロセスが非アクティブなときに積極的に物理メモリからスワップアウトします。
- 低い値:スワップの頻度が低く、インタラクティブな操作が頻繁にディスクにスワップされることを防ぎ、応答遅延を高めます。
最後に、なぜ SwapCached もページキャッシュの一部なのか?
これは、匿名ページ(Inactive (anon) および Active (anon))が最初にディスクにスワップアウトされた後、再度メモリに読み込まれると、元のスワップファイルがまだ存在するため、SwapCached もファイルバックページと見なすことができ、つまりページキャッシュに属します。このプロセスは以下の図のようになります。

ページキャッシュとバッファキャッシュ#
free コマンドを実行すると、buffers と cached という 2 つの列があり、「-/+ buffers/cache」という行もあります。
~ free -m
total used free shared buffers cached
Mem: 128956 96440 32515 0 5368 39900
-/+ buffers/cache: 51172 77784
Swap: 16002 0 16001
ここで、cached 列は現在のページキャッシュ(ページキャッシュ)の占有量を示し、buffers 列は現在のブロックキャッシュ(バッファキャッシュ)の占有量を示します。
一言で説明すると、ページキャッシュはファイルのページデータをキャッシュするために使用され、バッファキャッシュはブロックデバイス(ディスクなど)のブロックデータをキャッシュするために使用されます。
- ページは論理的な概念であるため、ページキャッシュはファイルシステムと同じレベルにあります;
- ブロックは物理的な概念であるため、バッファキャッシュはブロックデバイスドライバと同じレベルにあります。
ページキャッシュとバッファキャッシュの共通の目的はデータ I/O を加速することです: - データを書き込むときは、まずキャッシュに書き込み、書き込まれたページをダーティとしてマークし、外部ストレージにフラッシュします。これはキャッシュ書き込みメカニズムの write-back です(もう 1 つは write-through で、Linux ではデフォルトでは採用されていません);
- データを読み取るときは、まずキャッシュを読み取り、ヒットしない場合は外部ストレージから読み取り、読み取ったデータもキャッシュに追加します。オペレーティングシステムは常にすべての空きメモリをページキャッシュとバッファキャッシュに使用し、メモリが不足している場合も LRU などのアルゴリズムを使用してキャッシュページを排除します。
Linux 2.4 バージョンのカーネル以前は、ページキャッシュとバッファキャッシュは完全に分離されていました。しかし、ブロックデバイスの大部分はディスクであり、ディスク上のデータは大部分がファイルシステムを介して組織されているため、この設計により、多くのデータが 2 回キャッシュされ、メモリが無駄になります。
したがって、2.4 バージョンのカーネル以降、これら 2 つのキャッシュはほぼ統合されました。ファイルのページがページキャッシュに読み込まれると、バッファキャッシュはブロックがページを指すポインタを維持するだけで済みます。ファイルを表すブロックがない場合や、ファイルシステムをバイパスして直接操作するブロック(例えば dd コマンド)だけが、実際にバッファキャッシュに保存されます。
したがって、現在ページキャッシュを言及する場合、基本的にページキャッシュとバッファキャッシュの両方を指し、この記事以降は区別せず、直接ページキャッシュと呼びます。
以下の図は、32 ビット Linux システムにおけるページキャッシュの可能な構造を示しています。ブロックサイズは 1KB、ページサイズは 4KB です。

ページキャッシュ内の各ファイルは基数木(radix tree、実質的には多叉探索木)であり、木の各ノードは 1 つのページです。ファイル内のオフセットに基づいて、所在するページを迅速に特定できます。以下の図のように。基数木の原理については英語のウィキを参照できますが、ここでは詳しく説明しません。

ページキャッシュとプリリード#
オペレーティングシステムは、ページキャッシュに基づく読み取りキャッシュメカニズムを提供するプリリードメカニズム(PAGE_READAHEAD)を提供しています。例として:
- ユーザースレッドがディスク上のファイル A のオフセット 0-3KB の範囲内のデータを読み取るように要求した場合、ディスクの基本的な読み書き単位はブロック(4KB)であるため、オペレーティングシステムは少なくとも 0-4KB の内容を読み取ります。これはちょうど 1 つのページに収まります。