1. 文件系統的基本組成#
Linux 文件系統會為每個文件分配兩個數據結構:索引節點(index node)和目錄項(directory entry),它們主要用來記錄文件的元信息和目錄層次結構。
- 索引節點,也就是 inode,用來記錄文件的元信息,比如 inode 編號、文件大小、訪問權限、創建時間、修改時間、數據在磁碟的位置等等。索引節點是文件的唯一標識,它們之間一一對應,也同樣都會被存儲在硬碟中,所以索引節點同樣佔用磁碟空間。
- 目錄項,也就是 dentry,用來記錄文件的名字、索引節點指針以及與其他目錄項的層級關聯關係。多個目錄項關聯起來,就會形成目錄結構,但它與索引節點不同的是,目錄項是由內核維護的一個數據結構,不存放於磁碟,而是緩存在內存。
由於索引節點唯一標識一個文件,而目錄項記錄著文件的名字,所以目錄項和索引節點的關係是多對一,也就是說,一個文件可以有多個別名。比如,硬鏈接的實現就是多個目錄項中的索引節點指向同一個文件。
注意,目錄也是文件,也是用索引節點唯一標識,和普通文件不同的是,普通文件在磁碟裡面保存的是文件數據,而目錄文件在磁碟裡面保存子目錄或文件。
目錄項和目錄是一個東西嗎?
雖然名字很相近,但是它們不是一個東西,目錄是一個文件,持久化存儲在磁碟,而目錄項是內核一個數據結構,緩存在內存。
如果查詢目錄頻繁從磁碟讀,效率會很低,所以內核會把已經讀過的目錄用目錄項這個數據結構緩存在內存,下次再次讀到相同的目錄時,只需從內存讀就可以,大大提高了文件系統的效率。
注意,目錄項這個數據結構不只是表示目錄,也可以表示文件的。
那文件數據是如何存儲在磁碟的呢?
磁碟讀寫的最小單位是扇區,扇區的大小只有 512B 大小,很明顯,如果每次讀寫都以這麼小為單位,那這讀寫的效率會非常低。
所以,文件系統把多個扇區組成了一個邏輯塊,每次讀寫的最小單位就是邏輯塊(數據塊),Linux 中的邏輯塊大小為 4KB,也就是一次性讀寫 8 個扇區,這將大大提高了磁碟的讀寫的效率。
以上就是索引節點、目錄項以及文件數據的關係,下面這個圖就很好地展示了它們之間的關係:

索引節點是存儲在硬碟上的數據,那麼為了加速文件的訪問,通常會把索引節點加載到內存中。
另外,磁碟進行格式化的時候,會被分成三個存儲區域,分別是超級塊、索引節點區和數據塊區。
- 超級塊,用來存儲文件系統的詳細信息,比如塊個數、塊大小、空閒塊等等。
- 索引節點區,用來存儲索引節點;
- 數據塊區,用來存儲文件或目錄數據;
我們不可能把超級塊和索引節點區全部加載到內存,這樣內存肯定撐不住,所以只有當需要使用的時候,才將其加載進內存,它們加載進內存的時機是不同的:
- 超級塊:當文件系統掛載時進入內存;
- 索引節點區:當文件被訪問時進入內存;
2. 虛擬文件系統#
文件系統的種類眾多,而操作系統希望對用戶提供一個統一的接口,於是在用戶層與文件系統層引入了中間層,這個中間層就稱為虛擬文件系統(Virtual File System,VFS)。
VFS 定義了一組所有文件系統都支持的數據結構和標準接口,這樣程序員不需要了解文件系統的工作原理,只需要了解 VFS 提供的統一接口即可。
在 Linux 文件系統中,用戶空間、系統調用、虛擬文件系統、緩存、文件系統以及存儲之間的關係如下圖:
Linux 支持的文件系統也不少,根據存儲位置的不同,可以把文件系統分為三類:
- 磁碟的文件系統,它是直接把數據存儲在磁碟中,比如 Ext 2/3/4、XFS 等都是這類文件系統。
- 內存的文件系統,這類文件系統的數據不是存儲在硬碟的,而是佔用內存空間,我們經常用到的
/proc和/sys文件系統都屬於這一類,讀寫這類文件,實際上是讀寫內核中相關的數據。 - 網絡的文件系統,用來訪問其他計算機主機數據的文件系統,比如 NFS、SMB 等等。
文件系統首先要先掛載到某個目錄才可以正常使用,比如 Linux 系統在啟動時,會把文件系統掛載到根目錄。
3. 文件的使用#
我們從用戶角度來看文件的話,就是我們要怎麼使用文件?首先,我們得通過系統調用來打開一個文件。

讀取一個文件的過程:
- 首先用
open系統調用打開文件,open的參數中包含文件的路徑名和文件名。 - 使用
write寫數據,其中write使用open所返回的文件描述符,並不使用文件名作為參數。 - 使用完文件後,要用
close系統調用關閉文件,避免資源的泄露。
我們打開了一個文件後,操作系統會跟蹤進程打開的所有文件,所謂的跟蹤呢,就是操作系統為每個進程維護一個打開文件表,文件表裡的每一項代表「文件描述符」,所以說文件描述符是打開文件的標識。
操作系統在打開文件表中維護著打開文件的狀態和信息:
- 文件指針:系統跟蹤上次讀寫位置作為當前文件位置指針,這種指針對打開文件的某個進程來說是唯一的;
- 文件打開計數器:文件關閉時,操作系統必須重用其打開文件表條目,否則表內空間不夠用。因為多個進程可能打開同一個文件,所以系統在刪除打開文件條目之前,必須等待最後一個進程關閉文件,該計數器跟蹤打開和關閉的數量,當該計數為 0 時,系統關閉文件,刪除該條目;
- 文件磁碟位置:絕大多數文件操作都要求系統修改文件數據,該信息保存在內存中,以免每個操作都從磁碟中讀取;
- 訪問權限:每個進程打開文件都需要有一個訪問模式(創建、只讀、讀寫、添加等),該信息保存在進程的打開文件表中,以便操作系統能允許或拒絕之後的 I/O 請求;
在用戶視角裡,文件就是一個持久化的數據結構,但操作系統並不會關心你想存在磁碟上的任何的數據結構,操作系統的視角是如何把文件數據和磁碟塊對應起來。
所以,用戶和操作系統對文件的讀寫操作是有差異的,用戶習慣以字節的方式讀寫文件,而操作系統則是以數據塊來讀寫文件,那屏蔽掉這種差異的工作就是文件系統了。
我們來分別看一下,讀文件和寫文件的過程:
- 當用戶進程從文件讀取 1 個字節大小的數據時,文件系統則需要獲取字節所在的數據塊,再返回數據塊對應的用戶進程所需的數據部分。
- 當用戶進程把 1 個字節大小的數據寫進文件時,文件系統則找到需要寫入數據的數據塊的位置,然後修改數據塊中對應的部分,最後再把數據塊寫回磁碟。
所以說,文件系統的基本操作單位是數據塊。
4. 文件的存儲#
1. 連續空間存放方式#
連續空間存放方式顧名思義,文件存放在磁碟「連續的」物理空間中。這種模式下,文件的數據都是緊密相連,讀寫效率很高,因為一次磁碟尋道就可以讀出整個文件。
使用連續存放的方式有一個前提,必須先知道一個文件的大小,這樣文件系統才會根據文件的大小在磁碟上找到一塊連續的空間分配給文件。
所以,文件頭裡需要指定「起始塊的位置」和「長度」,有了這兩個信息就可以很好地表示文件存放方式是一塊連續的磁碟空間。
注意,此處說的文件頭,就類似於 Linux 的 inode。

連續空間存放的方式雖然讀寫效率高,但是有「磁碟空間碎片」和「文件長度不易擴展」的缺陷。
2. 非連續空間存放方式#
鏈表方式#
鏈表的方式存放是離散的,不用連續的,於是就可以消除磁碟碎片,可大大提高磁碟空間的利用率,同時文件的長度可以動態擴展。
隱式鏈表
實現的方式是文件頭要包含「第一塊」和「最後一塊」的位置,並且每個數據塊裡面留出一個指針空間,用來存放下一個數據塊的位置,這樣一個數據塊連著一個數據塊,從鏈頭開始就可以順著指針找到所有的數據塊,所以存放的方式可以是不連續的。

隱式鏈表的存放方式的缺點在於無法直接訪問數據塊,只能通過指針順序訪問文件,以及數據塊指針消耗了一定的存儲空間。隱式鏈接分配的穩定性較差,系統在運行過程中由於軟件或者硬件錯誤導致鏈表中的指針丟失或損壞,會導致文件數據的丟失。
顯式鏈接
它指把用於鏈接文件各數據塊的指針,顯式地存放在內存的一張鏈接表中,該表在整個磁碟僅設置一張,每個表項中存放鏈接指針,指向下一個數據塊號。
對於顯式鏈接的工作方式,我們舉個例子,文件 A 依次使用了磁碟塊 4、7、2、10 和 12 ,文件 B 依次使用了磁碟塊 6、3、11 和 14 。利用下圖中的表,可以從第 4 塊開始,順著鏈走到最後,找到文件 A 的全部磁碟塊。同樣,從第 6 塊開始,順著鏈走到最後,也能夠找出文件 B 的全部磁碟塊。最後,這兩個鏈都以一個不屬於有效磁碟編號的特殊標記(如 -1 )結束。內存中的這樣一個表格稱為文件分配表(File Allocation Table,FAT)。

由於查找記錄的過程是在內存中進行的,因而不僅顯著地提高了檢索速度,而且大大減少了訪問磁碟的次數。但也正是整個表都存放在內存中的關係,它的主要的缺點是不適用於大磁碟。
比如,對於 200GB 的磁碟和 1KB 大小的塊,這張表需要有 2 億項,每一項對應於這 2 億個磁碟塊中的一個塊,每項如果需要 4 個字節,那這張表要佔用 800MB 內存,很顯然 FAT 方案對於大磁碟而言不太合適。
索引方式#
索引的實現是為每個文件創建一個「索引數據塊」,裡面存放的是指向文件數據塊的指針列表,說白了就像書的目錄一樣,要找哪個章節的內容,看目錄查就可以。
另外,文件頭需要包含指向「索引數據塊」的指針,這樣就可以通過文件頭知道索引數據塊的位置,再通過索引數據塊裡的索引信息找到對應的數據塊。
創建文件時,索引塊的所有指針都設為空。當首次寫入第 i 塊時,先從空閒空間中取得一個塊,再將其地址寫到索引塊的第 i 個條目。

索引的方式優點在於:
- 文件的創建、增大、縮小很方便;
- 不會有碎片的問題;
- 支持順序讀寫和隨機讀寫;
由於索引數據也是存放在磁碟塊的,如果文件很小,明明只需一塊就可以存放的下,但還是需要額外分配一塊來存放索引數據,所以缺陷之一就是存儲索引帶來的開銷。
鏈式索引塊
如果文件很大,大到一個索引數據塊放不下索引信息,這時又要如何處理大文件的存放呢?我們可以通過組合的方式,來處理大文件的存。
先來看看鏈表 + 索引的組合,這種組合稱為「鏈式索引塊」,它的實現方式是在索引數據塊留出一個存放下一個索引數據塊的指針,於是當一個索引數據塊的索引信息用完了,就可以通過指針的方式,找到下一個索引數據塊的信息。那這種方式也會出現前面提到的鏈表方式的問題,萬一某個指針損壞了,後面的數據也就會無法讀取了。

還有另外一種組合方式是索引 + 索引的方式,這種組合稱為「多級索引塊」,實現方式是通過一個索引塊來存放多個索引數據塊,一層套一層索引,像極了俄羅斯套娃是吧。

3.Unix 文件的實現方式#
它是根據文件的大小,存放的方式會有所變化:
- 如果存放文件所需的數據塊小於 10 塊,則採用直接查找的方式;
- 如果存放文件所需的數據塊超過 10 塊,則採用一級間接索引方式;
- 如果前面兩種方式都不夠存放大文件,則採用二級間接索引方式;
- 如果二級間接索引也不夠存放大文件,這採用三級間接索引方式;
那麼,文件頭(Inode)就需要包含 13 個指針:
- 10 個指向數據塊的指針;
- 第 11 個指向索引塊的指針;
- 第 12 個指向二級索引塊的指針;
- 第 13 個指向三級索引塊的指針;
所以,這種方式能很靈活地支持小文件和大文件的存放:
- 對於小文件使用直接查找的方式可減少索引數據塊的開銷;
- 對於大文件則以多級索引的方式來支持,所以大文件在訪問數據塊時需要大量查詢;
4. 空閒空間管理#
如果我要保存一個數據塊,我應該放在硬碟上的哪個位置呢?難道需要將所有的塊掃描一遍,找個空的地方隨便放嗎?
那這種方式效率就太低了,所以針對磁碟的空閒空間也是要引入管理的機制,接下來介紹幾種常見的方法:
- 空閒表法
- 空閒鏈表法
- 位圖法
空閒表法#
空閒表法就是為所有空閒空間建立一張表,表內容包括空閒區的第一個塊號和該空閒區的塊個數,注意,這個方式是連續分配的。如下圖:

當請求分配磁碟空間時,系統依次掃描空閒表裡的內容,直到找到一個合適的空閒區域為止。當用戶撤銷一個文件時,系統回收文件空間。這時,也需順序掃描空閒表,尋找一個空閒表條目並將釋放空間的第一個物理塊號及它佔用的塊數填到這個條目中。
這種方法僅當有少量的空閒區時才有較好的效果。因為,如果存儲空間中有著大量的小的空閒區,則空閒表變得很大,這樣查詢效率會很低。另外,這種分配技術適用於建立連續文件。
空閒鏈表法#
我們也可以使用「鏈表」的方式來管理空閒空間,每一個空閒塊裡有一個指針指向下一個空閒塊,這樣也能很方便的找到空閒塊並管理起來。如下圖:

當創建文件需要一塊或幾塊時,就從鏈頭上依次取下一塊或幾塊。反之,當回收空間時,把這些空閒塊依次接到鏈頭上。
這種技術只要在主存中保存一個指針,令它指向第一個空閒塊。其特點是簡單,但不能隨機訪問,工作效率低,因為每當在鏈上增加或移動空閒塊時需要做很多 I/O 操作,同時數據塊的指針消耗了一定的存儲空間。
空閒表法和空閒鏈表法都不適合用於大型文件系統,因為這會使空閒表或空閒鏈表太大。
位圖法#
位圖是利用二進制的一位來表示磁碟中一個盤塊的使用情況,磁碟上所有的盤塊都有一個二進制位與之對應。
當值為 0 時,表示對應的盤塊空閒,值為 1 時,表示對應的盤塊已分配。它形式如下:
1111110011111110001110110111111100111 ...
在 Linux 文件系統就採用了位圖的方式來管理空閒空間,不僅用於數據空閒塊的管理,還用於 inode 空閒塊的管理,因為 inode 也是存儲在磁碟的,自然也要有對其管理。
5. 文件系統的結構#
用戶在創建一個新文件時,Linux 內核會通過 inode 的位圖找到空閒可用的 inode,並進行分配。要存儲數據時,會通過塊的位圖找到空閒的塊,並分配,但仔細計算一下還是有問題的。
數據塊的位圖是放在磁碟塊裡的,假設是放在一個塊裡,一個塊 4K,每位表示一個數據塊,共可以表示 4 * 1024 * 8 = 2^15 個空閒塊,由於 1 個數據塊是 4K 大小,那麼最大可以表示的空間為 2^15 * 4 * 1024 = 2^27 個 byte,也就是 128M。
也就是說按照上面的結構,如果採用「一個塊的位圖 + 一系列的塊」,外加「一個塊的 inode 的位圖 + 一系列的 inode 的結構」能表示的最大空間也就 128M,這太少了,現在很多文件都比這個大。
在 Linux 文件系統,把這個結構稱為一個塊組,那麼有 N 多的塊組,就能夠表示 N 大的文件。
下圖給出了 Linux Ext2 整個文件系統的結構和塊組的內容,文件系統都由大量塊組組成,在硬碟上相繼排布:

最前面的第一個塊是引導塊,在系統啟動時用於啟用引導,接著後面就是一個個連續的塊組了,塊組的內容如下:
- 超級塊,包含的是文件系統的重要信息,比如 inode 總個數、塊總個數、每個塊組的 inode 個數、每個塊組的塊個數等等。
- 塊組描述符,包含文件系統中各個塊組的狀態,比如塊組中空閒塊和 inode 的數目等,每個塊組都包含了文件系統中「所有塊組的組描述符信息」。
- 數據位圖和 inode 位圖, 用於表示對應的數據塊或 inode 是空閒的,還是被使用中。
- inode 列表,包含了塊組中所有的 inode,inode 用於保存文件系統中與各個文件和目錄相關的所有元數據。
- 數據塊,包含文件的有用數據。
你可以會發現每個塊組裡有很多重複的信息,比如超級塊和塊組描述符表,這兩個都是全局信息,而且非常的重要,這麼做是有兩個原因: - 如果系統崩潰破壞了超級塊或塊組描述符,有關文件系統結構和內容的所有信息都會丟失。如果有冗餘的副本,該信息是可能恢復的。
- 透過使文件和管理數據盡可能接近,減少了磁頭尋道和旋轉,這可以提高文件系統的性能。
不過,Ext2 的後續版本採用了稀疏技術。該做法是,超級塊和塊組描述符表不再存儲到文件系統的每個塊組中,而是只寫入到塊組 0、塊組 1 和其他 ID 可以表示為 3、 5、7 的幂的塊組中。
6. 目錄的存儲#
普通文件的塊裡面保存的是文件數據,而目錄文件的塊裡面保存的是目錄裡面一項一項的文件信息。
在目錄文件的塊中,最簡單的保存格式就是列表,就是一項一項地將目錄下的文件信息(如文件名、文件 inode、文件類型等)列在表裡。
列表中每一項就代表該目錄下的文件的文件名和對應的 inode,通過這個 inode,就可以找到真正的文件。

通常,第一項是「.」,表示當前目錄,第二項是「..」,表示上級目錄,接下來就是一項一項的文件名和 inode。
如果一個目錄有超級多的文件,我們要想在這個目錄下找文件,按照列表一項一項的找,效率就不高了。
於是,保存目錄的格式改成哈希表,對文件名進行哈希計算,把哈希值保存起來,如果我們要查找一個目錄下面的文件名,可以通過名稱取哈希。如果哈希能夠匹配上,就說明這個文件的信息在相應的塊裡面。
Linux 系統的 ext 文件系統就是採用了哈希表,來保存目錄的內容,這種方法的優點是查找非常迅速,插入和刪除也較簡單,不過需要一些預備措施來避免哈希衝突。
目錄查詢是通過在磁碟上反復搜索完成,需要不斷地進行 I/O 操作,開銷較大。所以,為了減少 I/O 操作,把當前使用的文件目錄緩存在內存,以後要使用該文件時只要在內存中操作,從而降低了磁碟操作次數,提高了文件系統的訪問速度。
7. 軟鏈接和硬鏈接#
有時候我們希望給某個文件取個別名,那麼在 Linux 中可以通過硬鏈接(Hard Link) 和軟鏈接(Symbolic Link) 的方式來實現,它們都是比較特殊的文件,但是實現方式也是不相同的。
硬鏈接#
硬鏈接是多個目錄項中的「索引節點」指向一個文件,也就是指向同一個 inode,但是 inode 是不可能跨越文件系統的,每個文件系統都有各自的 inode 數據結構和列表,所以硬鏈接是不可用於跨文件系統的。由於多個目錄項都是指向一個 inode,那麼只有刪除文件的所有硬鏈接以及源文件時,系統才會徹底刪除該文件。

軟鏈接#
軟鏈接相當於重新創建一個文件,這個文件有獨立的 inode,但是這個文件的內容是另外一個文件的路徑,所以訪問軟鏈接的時候,實際上相當於訪問到了另外一個文件,所以軟鏈接是可以跨文件系統的,甚至目標文件被刪除了,鏈接文件還是在的,只不過指向的文件找不到了而已。

8. 文件 I/O#
文件的讀寫方式各有千秋,對於文件的 I/O 分類也非常多,常見的有
- 緩衝與非緩衝 I/O
- 直接與非直接 I/O
- 阻塞與非阻塞 I/O VS 同步與異步 I/O
緩衝與非緩衝 I/O#
文件操作的標準庫是可以實現數據的緩存,那麼根據「是否利用標準庫緩衝」,可以把文件 I/O 分為緩衝 I/O 和非緩衝 I/O:
- 緩衝 I/O,利用的是標準庫的緩存實現文件的加速訪問,而標準庫再通過系統調用訪問文件。
- 非緩衝 I/O,直接通過系統調用訪問文件,不經過標準庫緩存。
這裡所說的「緩衝」特指標準庫內部實現的緩衝。
比方說,很多程序遇到換行時才真正輸出,而換行前的內容,其實就是被標準庫暫時緩存了起來,這樣做的目的是,減少系統調用的次數,畢竟系統調用是有 CPU 上下文切換的開銷的。
直接與非直接 I/O#
我們都知道磁碟 I/O 是非常慢的,所以 Linux 內核為了減少磁碟 I/O 次數,在系統調用後,會把用戶數據拷貝到內核中緩存起來,這個內核緩存空間也就是「頁緩存」,只有當緩存滿足某些條件的時候,才發起磁碟 I/O 的請求。
那麼,根據是「否利用操作系統的緩存」,可以把文件 I/O 分為直接 I/O 與非直接 I/O:
- 直接 I/O,不會發生內核緩存和用戶程序之間數據複製,而是直接經過文件系統訪問磁碟。
- 非直接 I/O,讀操作時,數據從內核緩存中拷貝給用戶程序,寫操作時,數據從用戶程序拷貝給內核緩存,再由內核決定什麼時候寫入數據到磁碟。
如果你在使用文件操作類的系統調用函數時,指定了 O_DIRECT 標誌,則表示使用直接 I/O。如果沒有設置過,默認使用的是非直接 I/O。
如果用了非直接 I/O 進行寫數據操作,內核什麼情況下才會把緩存數據寫入到磁碟?
以下幾種場景會觸發內核緩存的數據寫入磁碟:
- 在調用
write的最後,當發現內核緩存的數據太多的時候,內核會把數據寫到磁碟上; - 用戶主動調用
sync,內核緩存會刷到磁碟上; - 當內存十分緊張,無法再分配頁面時,也會把內核緩存的數據刷到磁碟上;
- 內核緩存的數據的緩存時間超過某個時間時,也會把數據刷到磁碟上;
阻塞與非阻塞 I/O VS 同步與異步 I/O#
為什麼把阻塞 / 非阻塞與同步與異步放一起說的呢?因為它們確實非常相似,也非常容易混淆,不過它們之間的關係還是有點微妙的。
先來看看阻塞 I/O,當用戶程序執行 read ,線程會被阻塞,一直等到內核數據準備好,並把數據從內核緩衝區拷貝到應用程序的緩衝區中,當拷貝過程完成,read 才會返回。
注意,阻塞等待的是「內核數據準備好」和「數據從內核態拷貝到用戶態」這兩個過程。過程如下圖:

知道了阻塞 I/O ,來看看非阻塞 I/O,非阻塞的 read 請求在數據未準備好的情況下立即返回,可以繼續往下執行,此時應用程序不斷輪詢內核,直到數據準備好,內核將數據拷貝到應用程序緩衝區,read 調用才可以獲取到結果。過程如下圖:
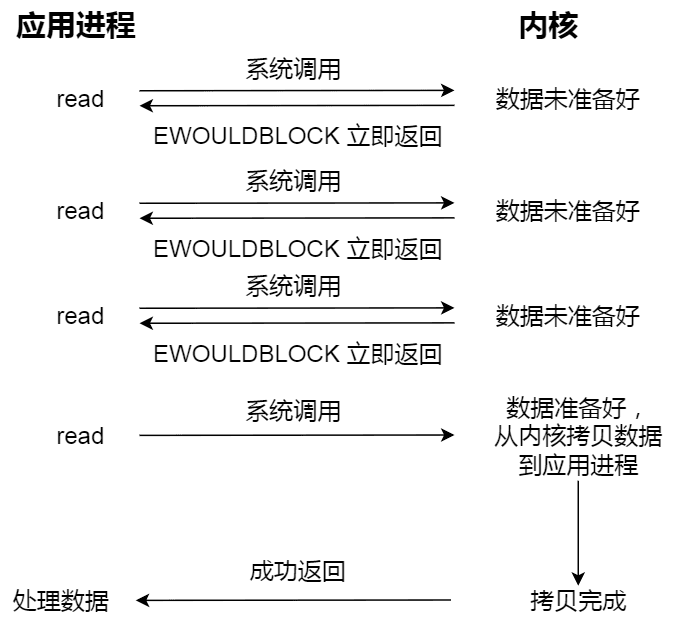
注意,這裡最後一次 read 調用,獲取數據的過程,是一個同步的過程,是需要等待的過程。這裡的同步指的是內核態的數據拷貝到用戶程序的緩衝區這個過程。
舉個例子,訪問管道或 socket 時,如果設置了 O_NONBLOCK 標誌,那麼就表示使用的是非阻塞 I/O 的方式訪問,而不做任何設置的話,默認是阻塞 I/O。
應用程序每次輪詢內核的 I/O 是否準備好,感覺有點傻乎乎,因為輪詢的過程中,應用程序啥也做不了,只是在循環。
為了解決這種傻乎乎輪詢方式,於是 I/O 多路復用技術就出來了,如 select、poll,它是通過 I/O 事件分發,當內核數據準備好時,再以事件通知應用程序進行操作。
這個做法大大改善了 CPU 的利用率,因為當調用了 I/O 多路復用接口,如果沒有事件發生,那麼當前線程就會發生阻塞,這時 CPU 會切換其他線程執行任務,等內核發現有事件到來的時候,會喚醒阻塞在 I/O 多路復用接口的線程,然後用戶可以進行後續的事件處理。
整個流程要比阻塞 IO 要複雜,似乎也更浪費性能。但 I/O 多路復用接口最大的優勢在於,用戶可以在一個線程內同時處理多個 socket 的 IO 請求(參見:I/O 多路復用:select/poll/epoll (opens new window))。用戶可以註冊多個 socket,然後不斷地調用 I/O 多路復用接口讀取被激活的 socket,即可達到在同一個線程內同時處理多個 IO 請求的目的。而在同步阻塞模型中,必須通過多線程的方式才能達到這個目的。
下圖是使用 select I/O 多路復用過程。注意,read 獲取數據的過程(數據從內核態拷貝到用戶態的過程),也是一個同步的過程,需要等待:
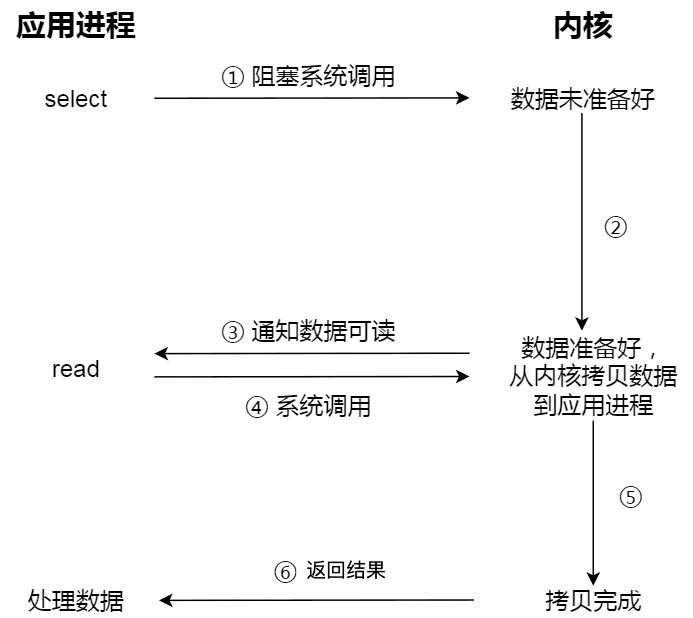
實際上,無論是阻塞 I/O、非阻塞 I/O,還是基於非阻塞 I/O 的多路復用都是同步調用。因為它們在 read 調用時,內核將數據從內核空間拷貝到應用程序空間,過程都是需要等待的,也就是說這個過程是同步的,如果內核實現的拷貝效率不高,read 調用就會在這個同步過程中等待比較長的時間。
而真正的異步 I/O 是「內核數據準備好」和「數據從內核態拷貝到用戶態」這兩個過程都不用等待。
當我們發起 aio_read 之後,就立即返回,內核自動將數據從內核空間拷貝到應用程序空間,這個拷貝過程同樣是異步的,內核自動完成的,和前面的同步操作不一樣,用戶程序並不需要主動發起拷貝動作。過程如下圖:

下面這張圖,總結了以上幾種 I/O 模型:

在前面我們知道了,I/O 是分為兩個過程的:
- 數據準備的過程
- 數據從內核空間拷貝到用戶進程緩衝區的過程
阻塞 I/O 會阻塞在「過程 1 」和「過程 2」,而非阻塞 I/O 和基於非阻塞 I/O 的多路復用只會阻塞在「過程 2」,所以這三個都可以認為是同步 I/O。
異步 I/O 則不同,「過程 1 」和「過程 2 」都不会阻塞。
9.Page Cache#
Page Cache 是什麼?#
為了理解 Page Cache,我們不妨先看一下 Linux 的文件 I/O 系統,如下圖所示:

上圖中,紅色部分為 Page Cache。可見 Page Cache 的本質是由 Linux 內核管理的內存區域。我們通過 mmap 以及 buffered I/O 將文件讀取到內存空間實際上都是讀取到 Page Cache 中。
如何查看系統的 Page Cache?#
通過讀取 /proc/meminfo 文件,能夠實時獲取系統內存情況:
$ cat /proc/meminfo
...
Buffers: 1224 kB
Cached: 111472 kB
SwapCached: 36364 kB
Active: 6224232 kB
Inactive: 979432 kB
Active(anon): 6173036 kB
Inactive(anon): 927932 kB
Active(file): 51196 kB
Inactive(file): 51500 kB
...
Shmem: 10000 kB
...
SReclaimable: 43532 kB
...
根據上面的數據,你可以簡單得出這樣的公式(等式兩邊之和都是 112696 KB):
Buffers + Cached + SwapCached = Active(file) + Inactive(file) + Shmem + SwapCached
兩邊等式都是 Page Cache,即:
Page Cache = Buffers + Cached + SwapCached
通過閱讀下面的小節,就能理解為什麼 SwapCached 與 Buffers 也是 Page Cache 的一部分。
page 與 Page Cache#
page 是內存管理分配的基本單位, Page Cache 由多個 page 構成。page 在操作系統中通常為 4KB 大小(32bits/64bits),而 Page Cache 的大小則為 4KB 的整數倍。
另一方面,並不是所有 page 都被組織為 Page Cache。
Linux 系統上供用戶可訪問的內存分為兩種類型,即:
- File-backed pages:文件備份頁也就是 Page Cache 中的 page,對應於磁碟上的若干數據塊;對於這些頁最大的问题是脏页回盘;
- Anonymous pages:匿名頁不對應磁碟上的任何磁碟數據塊,它們是進程的運行是內存空間(例如方法棧、局部變量表等屬性);
為什麼 Linux 不把 Page Cache 稱為 block cache,這不是更好嗎?
這是因為從磁碟中加載到內存的數據不僅僅放在 Page Cache 中,還放在 buffer cache 中。
例如通過 Direct I/O 技術的磁碟文件就不會進入 Page Cache 中。當然,這個問題也有 Linux 歷史設計的原因,畢竟這只是個稱呼,含義隨著 Linux 系統的演進也逐漸不同。
下面比較一下 File-backed pages 與 Anonymous pages 在 Swap 機制下的性能。
內存是一種珍惜資源,當內存不夠用時,內存管理單元(Memory Mangament Unit)需要提供調度算法來回收相關內存空間。內存空間回收的方式通常就是 swap,即交換到持久化存儲設備上。
File-backed pages(Page Cache)的內存回收代價較低。Page Cache 通常對應於一個文件上的若干順序塊,因此可以通過順序 I/O 的方式落盤。另一方面,如果 Page Cache 上沒有進行寫操作(所謂的沒有脏頁),甚至不會將 Page Cache 回盤,因為數據的內容完全可以通過再次讀取磁碟文件得到。
Page Cache 的主要難點在於脏頁回盤,這個內容會在後面進行詳細說明。
Anonymous pages 的內存回收代價較高。這是因為 Anonymous pages 通常隨機地寫入持久化交換設備。另一方面,無論是否有寫操作,為了確保數據不丟失,Anonymous pages 在 swap 時必須持久化到磁碟。
Swap 與缺頁中斷#
Swap 機制指的是當物理內存不夠用,內存管理單元(Memory Mangament Unit,MMU)需要提供調度算法來回收相關內存空間,然後將清理出來的內存空間給當前內存申請方。
Swap 機制存在的本質原因是 Linux 系統提供了虛擬內存管理機制,每一個進程認為其獨占內存空間,因此所有進程的內存空間之和遠遠大於物理內存。所有進程的內存空間之和超過物理內存的部分就需要交換到磁碟上。
操作系統以 page 為單位管理內存,當進程發現需要訪問的數據不在內存時,操作系統可能會將數據以頁的方式加載到內存中。上述過程被稱為缺頁中斷,當操作系統發生缺頁中斷時,就會通過系統調用將 page 再次讀到內存中。
但主內存的空間是有限的,當主內存中不包含可以使用的空間時,操作系統會從選擇合適的物理內存頁驅逐回磁碟,為新的內存頁讓出位置,選擇待驅逐頁的過程在操作系統中叫做頁面替換(Page Replacement),替換操作又會觸發 swap 機制。
如果物理內存足夠大,那麼可能不需要 Swap 機制,但是 Swap 在這種情況下還是有一定優勢:對於有發生內存泄漏幾率的應用程序(進程),Swap 交換分區更是重要,這可以確保內存泄露不至於導致物理內存不夠用,最終導致系統崩潰。但內存泄露會引起頻繁的 swap,此時非常影響操作系統的性能。
Linux 通過一個 swappiness 參數來控制 Swap 機制:這個參數值可為 0-100,控制系統 swap 的優先級:
- 高數值:較高頻率的 swap,進程不活躍時主動將其轉換出物理內存。
- 低數值:較低頻率的 swap,這可以確保交互式不因為內存空間頻繁地交換到磁碟而提高響應延遲。
最後,為什麼 SwapCached 也是 Page Cache 的一部分?
這是因為當匿名頁(Inactive (anon) 以及 Active (anon))先被交換(swap out)到磁碟上後,然後再加載回(swap in)內存中,由於讀入到內存後原來的 Swap File 還在,所以 SwapCached 也可以認為是 File-backed page,即屬於 Page Cache。這個過程如下圖所示。

Page Cache 與 buffer cache#
執行 free 命令,注意到會有兩列名為 buffers 和 cached,也有一行名為 “-/+ buffers/cache”。
~ free -m
total used free shared buffers cached
Mem: 128956 96440 32515 0 5368 39900
-/+ buffers/cache: 51172 77784
Swap: 16002 0 16001
其中,cached 列表示當前的頁緩存(Page Cache)佔用量,buffers 列表示當前的塊緩存(buffer cache)佔用量。
用一句話來解釋:Page Cache 用於緩存文件的頁數據,buffer cache 用於緩存塊設備(如磁碟)的塊數據。
- 頁是邏輯上的概念,因此 Page Cache 是與文件系統同級的;
- 塊是物理上的概念,因此 buffer cache 是與塊設備驅動程序同級的。
Page Cache 與 buffer cache 的共同目的都是加速數據 I/O: - 寫數據時首先寫到緩存,將寫入的頁標記為 dirty,然後向外部存儲 flush,也就是緩存寫機制中的 write-back(另一種是 write-through,Linux 默認情況下不採用);
- 讀數據時首先讀取緩存,如果未命中,再去外部存儲讀取,並且將讀取來的數據也加入緩存。操作系統總是積極地將所有空閒內存都用作 Page Cache 和 buffer cache,當內存不夠用時也會用 LRU 等算法淘汰緩存頁。
在 Linux 2.4 版本的內核之前,Page Cache 與 buffer cache 是完全分離的。但是,塊設備大多是磁碟,磁碟上的數據又大多通過文件系統來組織,這種設計導致很多數據被緩存了兩次,浪費內存。
所以在 2.4 版本內核之後,兩塊緩存近似融合在了一起:如果一個文件的頁加載到了 Page Cache,那麼同時 buffer cache 只需要維護塊指向頁的指針就可以了。只有那些沒有文件表示的塊,或者繞過了文件系統直接操作(如 dd 命令)的塊,才會真正放到 buffer cache 裡。
因此,我們現在提起 Page Cache,基本上都同時指 Page Cache 和 buffer cache 兩者,本文之後也不再區分,直接統稱為 Page Cache。
下圖近似地示出 32-bit Linux 系統中可能的一種 Page Cache 結構,其中 block size 大小為 1KB,page size 大小為 4KB。

Page Cache 中的每個文件都是一棵基數樹(radix tree,本質上是多叉搜索樹),樹的每個節點都是一個頁。根據文件內的偏移量就可以快速定位到所在的頁,如下圖所示。關於基數樹的原理可以參見英文維基,這裡就不細說了。

Page Cache 與預讀#
操作系統為基於 Page Cache 的讀緩存機制提供預讀機制(PAGE_READAHEAD),一個例子是:
- 用戶線程僅僅請求讀取磁碟上文件 A 的 offset 為 0-3KB 範圍內的數據,由於磁碟的基本讀寫單位為 block(4KB),於是操作系統至少會讀 0-4KB 的內容,這恰好可以在一個 page 中裝下。
- 但是操作系統出於局部性原理會選擇將磁碟塊 offset [4KB,8KB)、[8KB,12KB) 以及 [12KB,16KB) 都加載到內存,於是額外在內存中申請了 3 個 page;
下圖代表了操作系統的預讀機制:

上圖中,應用程序利用 read 系統調動讀取 4KB 數據,實際上內核使用 readahead 機制完成了 16KB 數據的讀取。
Page Cache 與文件持久化的一致性 & 可靠性#
現代 Linux 的 Page Cache 正如其名,是對磁碟上 page(頁)的內存緩存,同時可以用於讀 / 寫操作。
任何系統引入緩存,就會引發一致性問題:內存中的數據與磁碟中的數據不一致,例如常見後端架構中的 Redis 緩存與 MySQL 數據庫就存在一致性問題。
Linux 提供多種機制來保證數據一致性,但無論是單機上的內存與磁碟一致性,還是分佈式組件中節點 1 與節點 2 、節點 3 的數據一致性問題,理解的關鍵是 trade-off:吞吐量與數據一致性保證是一對矛盾。
首先,需要我們理解一下文件的數據。文件 = 數據 + 元數據。元數據用來描述文件的各種屬性,也必須存儲在磁碟上。因此,我們說保證文件一致性其實包含了兩個方面:數據一致 + 元數據一致。
文件的元數據包括:文件大小、創建時間、訪問時間、屬主屬組等信息。
我們考慮如下一致性問題:如果發生寫操作並且對應的數據在 Page Cache 中,那麼寫操作就會直接作用於 Page Cache 中,此時如果數據還沒刷新到磁碟,那麼內存中的數據就領先於磁碟,此時對應 page 就被稱為 Dirty page。
當前 Linux 下以兩種方式實現文件一致性:
- Write Through(寫穿):向用戶層提供特定接口,應用程序可主動調用接口來保證文件一致性;
- Write back(寫回):系統中存在定期任務(表現形式為內核線程),周期性地同步文件系統中文件脫數據塊,這是默認的 Linux 一致性方案;
上述兩種方式最終都依賴於系統調用,主要分為如下三種系統調用:
fsync (fd):將 fd 代表的文件的脫數據和脫元數據全部刷新至磁碟中。
fdatasync (fd):將 fd 代表的文件的脫數據刷新至磁碟,同時對必要的元數據刷新至磁碟中,這裡所說的必要的概念是指:對接下來訪問文件有關鍵作用的信息,如文件大小,而文件修改時間等不屬於必要信息
sync ():則是對系統中所有的脫的文件數據元數據刷新至磁碟中
上述三種系統調用可以分別由用戶進程與內核進程發起。下面我們研究一下內核線程的相關特性。
- 創建的針對回寫任務的內核線程數由系統中持久存儲設備決定,為每個存儲設備創建單獨的刷新線程;
- 關於多線程的架構問題,Linux 內核採取了 Lighthttp 的做法,即系統中存在一個管理線程和多個刷新線程(每個持久存儲設備對應一個刷新線程)。管理線程監控設備上的脫頁面情況,若設備一段時間內沒有產生脫頁面,就銷毀設備上的刷新線程;若監測到設備上有脫頁面需要回寫且尚未為該設備創建刷新線程,那麼創建刷新線程處理脫頁面回寫。而刷新線程的任務較為單調,只負責將設備中的脫頁面回寫至持久存儲設備中。
- 刷新線程刷新設備上脫頁面大致設計如下:
- 每個設備保存脫文件鏈表,保存的是該設備上存儲的脫文件的 inode 節點。所謂的回寫文件脫頁面即回寫該 inode 鏈表上的某些文件的脫頁面;
- 系統中存在多個回寫時機,第一是應用程序主動調用回寫接口(fsync,fdatasync 以及 sync 等),第二管理線程周期性地喚醒設備上的回寫線程進行回寫,第三是某些應用程序 / 內核任務發現內存不足時要回收部分緩存頁面而事先進行脫頁面回寫,設計一個統一的框架來管理這些回寫任務非常有必要。
Write Through 與 Write back 在持久化的可靠性上有所不同:
- Write Through 以犧牲系統 I/O 吞吐量作為代價,向上層應用確保一旦寫入,數據就已經落盤,不會丟失;
- Write back 在系統發生宕機的情況下無法確保數據已經落盤,因此存在數據丟失的問題。不過,在程序掛了,例如被 kill -9,Page Cache 中的數據操作系統還是會確保落盤;
Page Cache 的優劣勢#
Page Cache 的優勢#
1. 加快數據訪問
如果數據能夠在內存中進行緩存,那麼下一次訪問就不需要通過磁碟 I/O 了,直接命中內存緩存即可。
由於內存訪問比磁碟訪問快很多,因此加快數據訪問是 Page Cache 的一大優勢。
2. 減少 I/O 次數,提高系統磁碟 I/O 吞吐量
得益於 Page Cache 的緩存以及預讀能力,而程序又往往符合局部性原理,因此通過一次 I/O 將多個 page 裝入 Page Cache 能夠減少磁碟 I/O 次數, 進而提高系統磁碟 I/O 吞吐量。
Page Cache 的劣勢#
page cache 也有其劣勢,最直接的缺點是需要佔用額外物理內存空間,物理內存在比較緊俏的時候可能會導致頻繁的 swap 操作,最終導致系統的磁碟 I/O 負載的上升。
Page Cache 的另一個缺陷是對應用層並沒有提供很好的管理 API,幾乎是透明管理。應用層即使想優化 Page Cache 的使用策略也很難進行。因此一些應用選擇在用戶空間實現自己的 page 管理,而不使用 page cache,例如 MySQL InnoDB 存儲引擎以 16KB 的頁進行管理。
Page Cache 最後一個缺陷是在某些應用場景下比 Direct I/O 多一次磁碟讀 I/O 以及磁碟寫 I/O。
Direct I/O 即直接 I/O。其名字中的” 直接” 二字用於區分使用 page cache 機制的緩存 I/O。
- 緩存文件 I/O:用戶空間要讀寫一個文件並不直接與磁碟交互,而是中間夾了一層緩存,即 page cache;
- 直接文件 I/O:用戶空間讀取的文件直接與磁碟交互,沒有中間 page cache 層;
“直接” 在這裡還有另一層語義:其他所有技術中,數據至少需要在內核空間存儲一份,但是在 Direct I/O 技術中,數據直接存儲在用戶空間中,繞過了內核。
Direct I/O 模式如下圖所示:

此時用戶空間直接通過 DMA 的方式與磁碟以及網卡進行數據拷貝。
Direct I/O 的讀寫非常有特點:
- Write 操作:由於其不使用 page cache,所以其進行寫文件,如果返回成功,數據就真的落盤了(不考慮磁碟自帶的緩存);
- Read 操作:由於其不使用 page cache,每次讀操作是真的從磁碟中讀取,不會從文件系統的緩存中讀取。
零拷貝#
磁碟讀寫速度相差內存 10 倍以上,所以針對優化磁碟的技術非常的多,比如零拷貝、直接 I/O、異步 I/O 等等,這些優化的目的就是為了提高系統的吞吐量,另外操作系統內核中的磁碟高速緩存區,可以有效的減少磁碟的訪問次數。
DMA 技術?#
在進行 I/O 設備和內存的數據傳輸的時候,數據搬運的工作全部交給 DMA 控制器,而 CPU 不再參與任何與數據搬運相關的事情,這樣 CPU 就可以去處理別的事務。
使用 DMA 控制器進行數據傳輸的過程:
具體過程:
- 用戶進程調用 read 方法,向操作系統發出 I/O 請求,請求讀取數據到自己的內存緩衝區中,進程進入阻塞狀態;
- 操作系統收到請求後,進一步將 I/O 請求發送 DMA,然後讓 CPU 執行其他任務;
- DMA 進一步將 I/O 請求發送給磁碟;
- 磁碟收到 DMA 的 I/O 請求,把數據從磁碟讀取到磁碟控制器的緩衝區中,當磁碟控制器的緩衝區被讀滿後,向 DMA 發起中斷信號,告知自己緩衝區已滿;
- **DMA 收到磁碟的信號,將磁碟控制器緩衝區中的數據拷貝到